
|
|
Machine Learning for the LHC
LHC physics, like many other field in and around particle physics is living through an exciting, data-driven era. As theorists we can come up with ideas for physics beyond the Standard Model, motivated by dark matter or the matter-antimatter asymmetry or whatever else keeps us up at night, and immediately try it on LHC data. Even if we do not have access to the actual data we can devise search strategies using a simulation chain based on first principles and then hand our ideas and tools over to our experimental friends. The scientific challenge is that we have to understand the basic structure of LHC data, its (precision) simulation, and the best ways of using huge amounts of data. This immediately brings us to machine learning as a great tool for particle physicists. In our group we develop and apply modern data analysis tools in four ways, where this number should be increasing. Here is a list of papers we published on machine learning applications:
We are especially happy to publish our hep-ml lecture notes, based on a master-level course and with a set of tutorial problems (2022). The notes start with a very basic introduction to modern neural networks for particle physicists and then introduces classification, unsupervised training, generative networks, and conditional generative networks for inverse problems. Some, but not all tools have been in developed in Heidelberg, and we expect the lecture notes to further grow over the coming years. For the most up-to-date version, use the link on this homepage. |
 |
Jet and Event Classification
Multi-variate analysis methods have a long tradition in particle physics. If we use sub-jet physics as an example, we want to ask the question what kind of quark or gluon initiated an observed jet. Traditionally, this question is asked in relation to bottom quarks, which can be identified by a displaced decay vertex and one or more leptons inside the hadronic jets. From a theory and experimental perspective the cleanest signature are boosted top quarks. The original HEPTopTagger approach asks for two mass drops, one from the top decay and one from the W-decay. We know that this tagger can be hugely improved when we include a wealth of kinematic observables, some directly and some algorithmically derived from the energies and the momenta of the subjets. The obvious question is why we need to construct these high-level observables and if we cannot just feed the 4-momenta of the subjets into a classification algorithm. As a matter of fact, we can do exactly that. The next question is if we really need to train our classification on data where we know the truth label, or if we can just look for jets which look as little like QCD as possible. That is the second aspect we are working on these days. Many aspects we have been studying are related to uncertainties, symmetries, latent representations, data augmentations, and can be viewed as explainable AI for particle physicists. This series of papers has been made possible by Sven Bollweg, Anja Butter, Sascha Diefenbacher, Barry Dillon, Friedrich Feiden, Hermann Frost, Manuel Haussmann, Theo Heimel, Gregor Kasieczka, Nicholas Kiefer, Michel Luchmann, Tanmoy Modak, Michael Russell, Torben Schell, Christof Sauer, Peter Sorrenson, Jennie Thompson, Lorenz Vogel, and more students and postdocs.
Both based on compact latent spacess (2023) we can combine normalizing autoencoders with contrastive learning to search for anomalies with a bias on the underlying symmetries, invariances, and patterns. We show how this helps in searching for anomalous jets, not in all generality, but with dark matter signals in mind. |
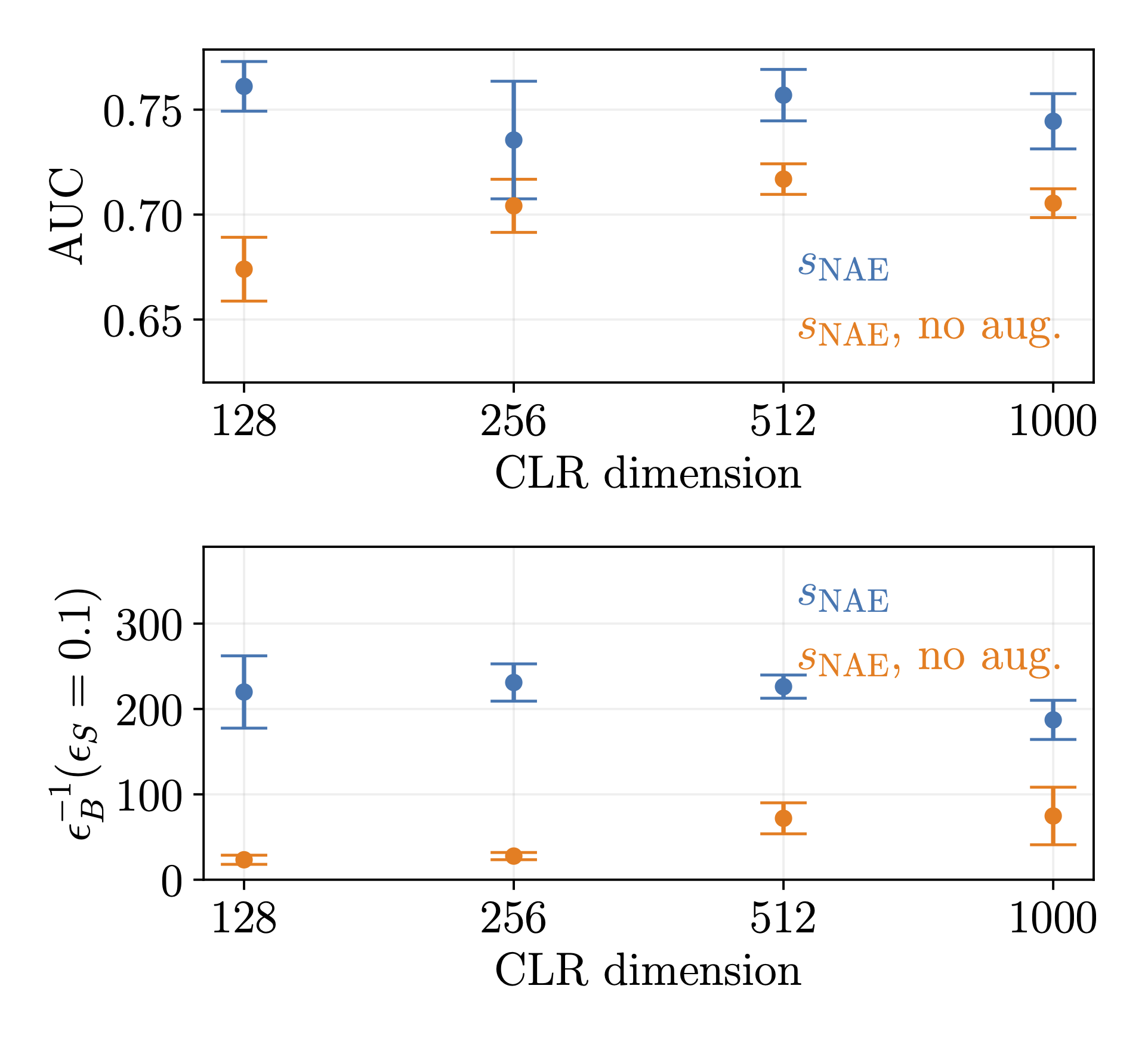 |
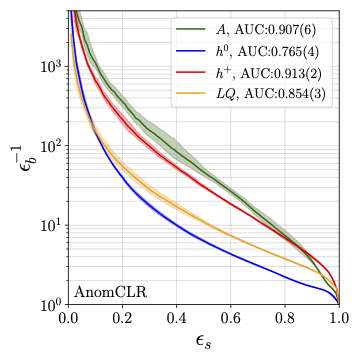
Model-independent searches for anomalous events (2023) are one of the big unsolved problems at the LHC, as they define the idea of triggering in the language of data science. We use contrastive learning on augmented background events to define a representation space which allows us to identify anomalous events based on basic properties. This method goes beyond density estimation to define anomalies and attempts to define a model-agnostic implicit bias. |
 |
Resilience is a big problems for LHC classifiers (2022). One reason is that they are usually trained on simulations, which are excellent, but might still lead to a generalization error. This leads to a serious problem if the difference between training and test data is strongly correlated with relevant classification features. We show how networks can be trained on a continuous interpolation between training samples, including an error analysis using Bayesian networks. Continuous interpolation between training and test data might allow us to take a fresh look at calibration strategies. |
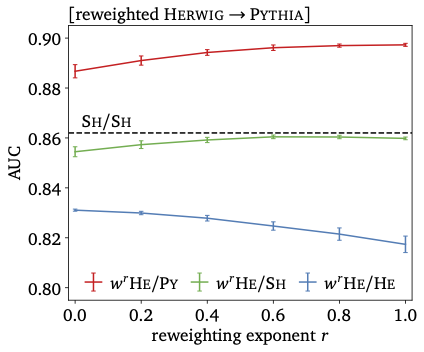 |
Normalizing autoencoder for LHC triggers, tested on dark jets (2022). We develop the first autoencoder which identified jets with higher and with lower complexity than QCD jets and without a significant dependence on the data preprocessing. Its architecture is the same as the usual autoencoder, but with an energy-based training. This training uses a combination of latent and reconstruction space Markov chains. |
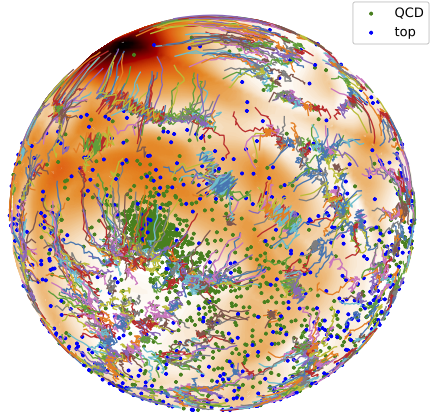 |
Comparison of different density-based anomaly serches for jets (2022). The challenge of anomaly searches at the LHC, for instance applied to jets, is that out-of-distribution searches cannot be used to analyze phase space configurations of a quantum process. Instead, we need to identify configurations with a small probability density extracted by unsupervised training. We compare a classic k-means-based method with a Dirichlet autoencoder and an INN on two new, dark-matter-inspired jet datasets. |
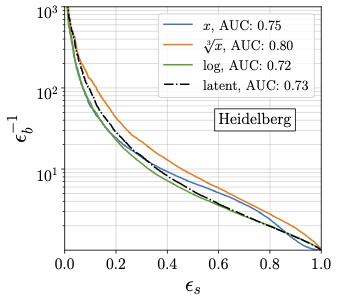 |
The first application of contrastive learning to LHC physics (2021). The idea is to train a network to incorporate symmetries like rotations, translations, and permutations in its representations of QCD jets. In addition, the network also learns infrared and collinear safety as fundamental properties of the underlying quantum field theory. The way these symmetries and augmentations are encoded in the latent representation can be studied using linear classifier tests. |
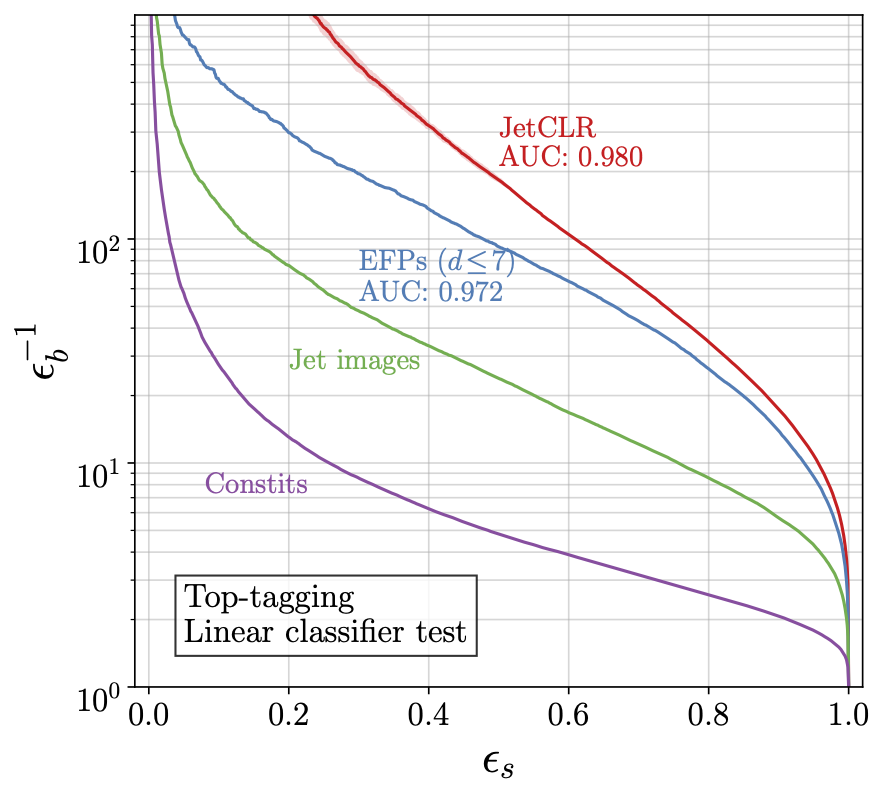 |
Using unsupervised learning to reduce the model dependence in searches for anomalous and hard-to-detect Higgs decays (2021). For hidden valley models the number of parameters in the signal hypothesis is large, and their impact on the analysis is sizeable. We show how an unsupervised search method based on appropriate observables is an attractive alternative to supervised search methods based on unknown model parameters. |
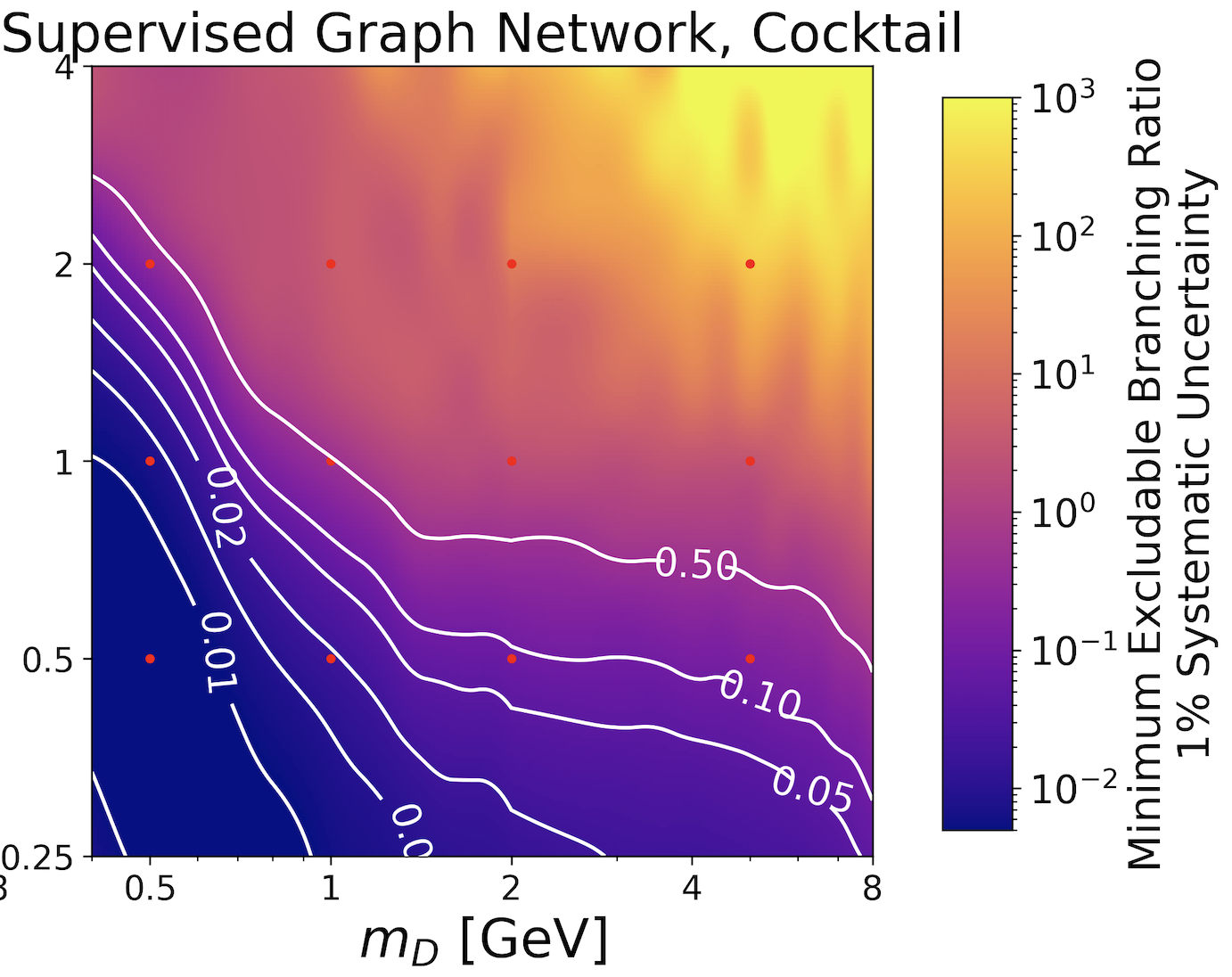 |
Constructing a symmetric autoencoder with better latent spaces (2021). We know from our earlier study that it is possible to extract top jets from a QCD jet sample, essentially based on the compressibility of the encoded information. To apply unsupervized classification the other way around, we need to define a nice latent space and access this latent space rather than the reconstruction loss. And then it works. |
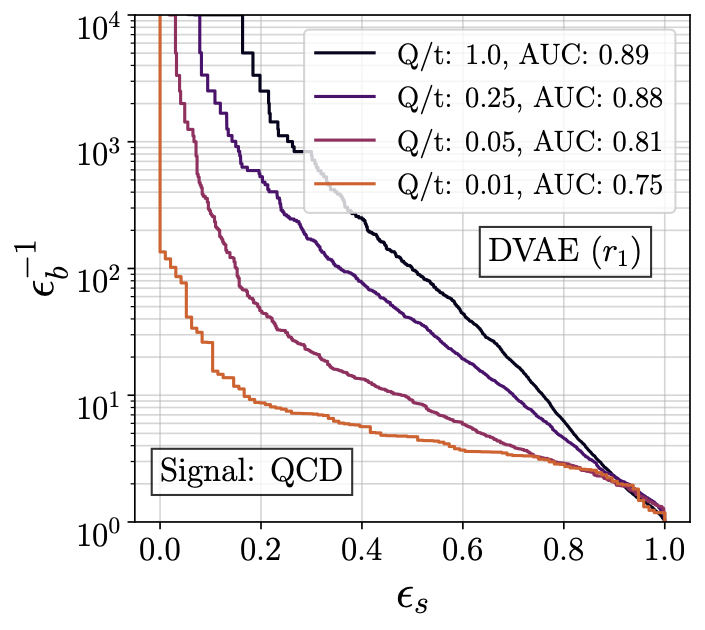 |
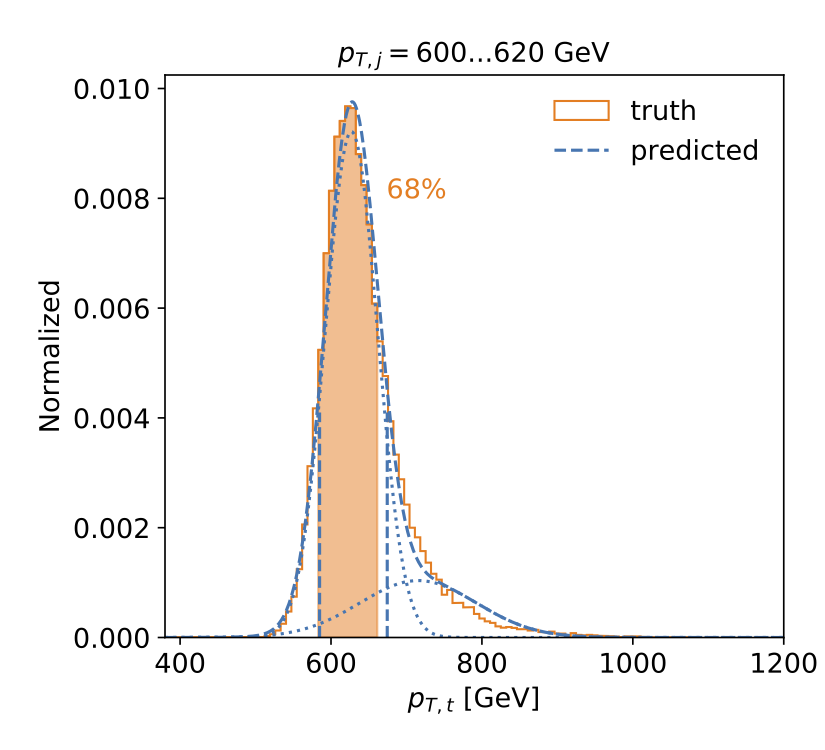
Measurement of jet momenta with uncertainties and calibration of regression tools with Bayesian networks (2020). The measurement by the regression network tracks statistical and systematic uncertainties from the training data. We propose to calibrate the network in a straightforward way through the smearing introduced by the measurement of labels. |
 |
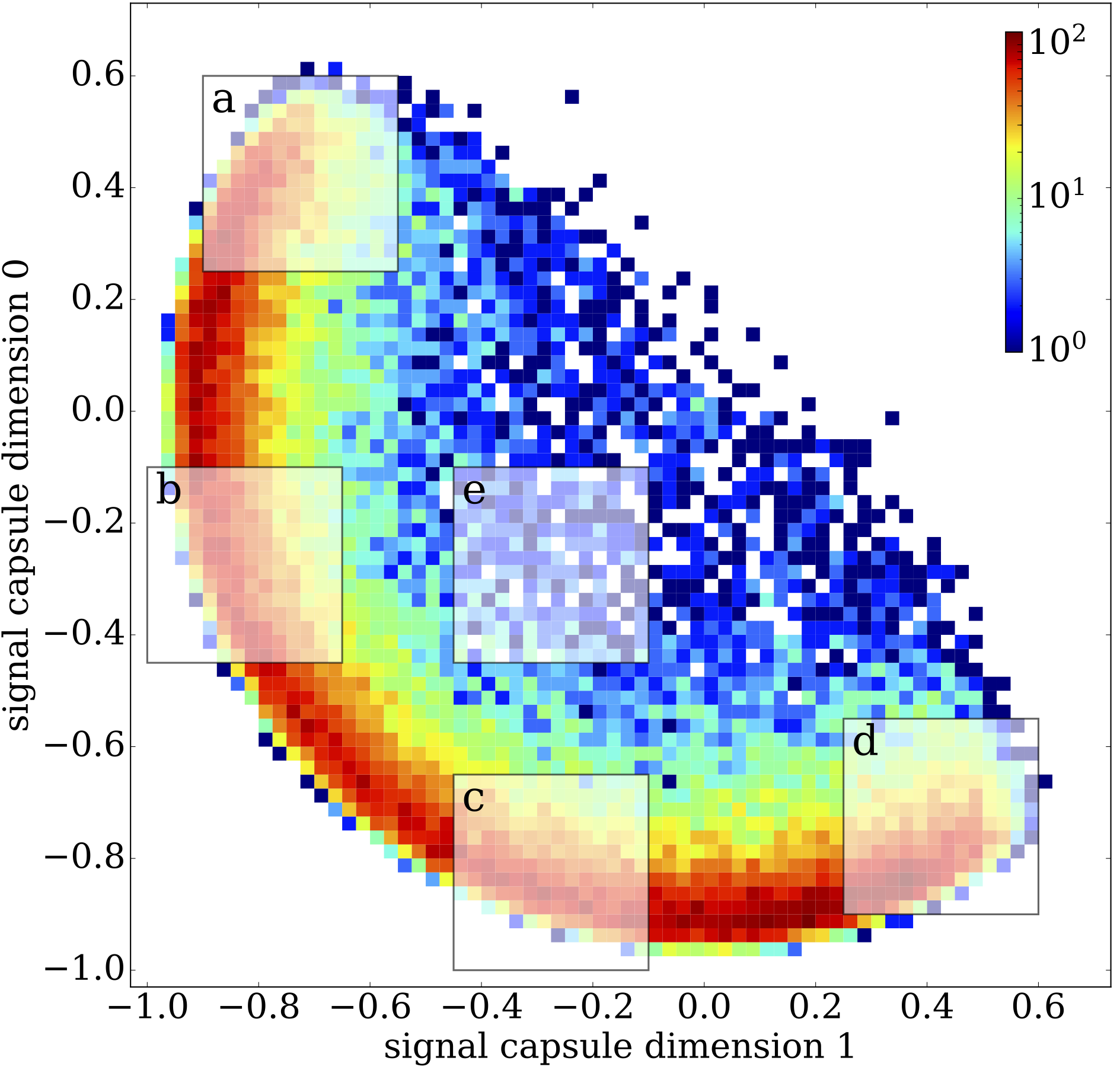
Jet and event classification with capsule networks (2019). Such capsule networks are a natural extension of (scalar) convolutional networks and can be used to analyse sparse sets of detector objects, each represented by a sparse calorimeter image. |
 |
Top tagging with uncertainties using Bayesian classification networks (2019). Such a tagger provides a classification output and a jet-wise error estimate on the classification outcome. While statistical uncertainties from a limited training sample are easily traced, systematic uncertainties lead to a correlation of the central value and the uncertainties, all the way to adversarial examples. |
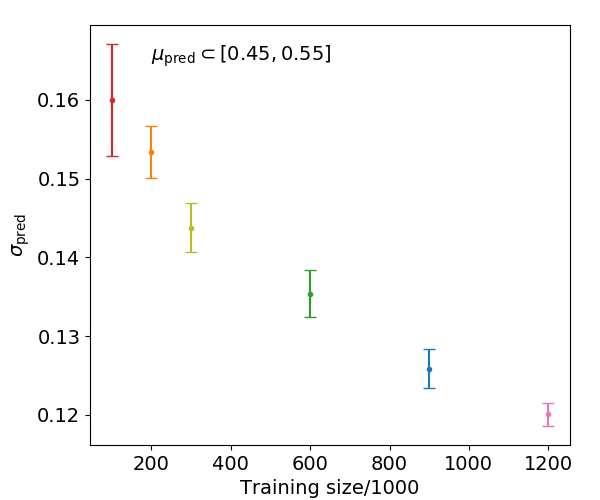 |
Top-tagging community paper (2019) comparing a wide range of top taggers, from image-based to 4-vector-based and theory-motivated tagging approaches. We show their respective performances for a standard data set and find that there are many ways of contructing highly performing taggers ready to hit LHC data. |
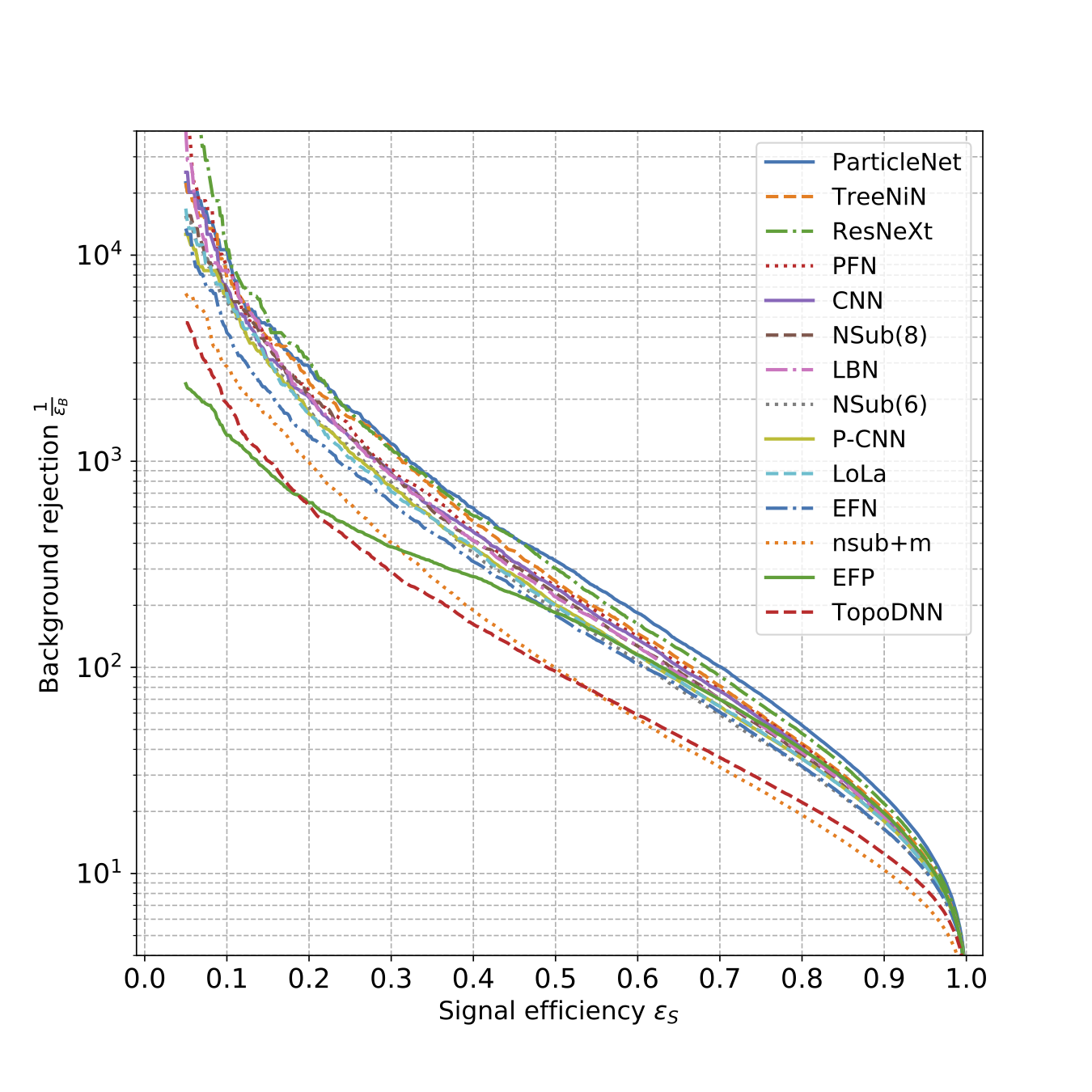 |
LoLa-based quark-gluon tagger (2018) showing that the same 4-vector-based architecture can be used to distinguish hard processes with preferably quark or gluon jets. The issue is how to design a high-performance tagger in the presence of detector effects. |
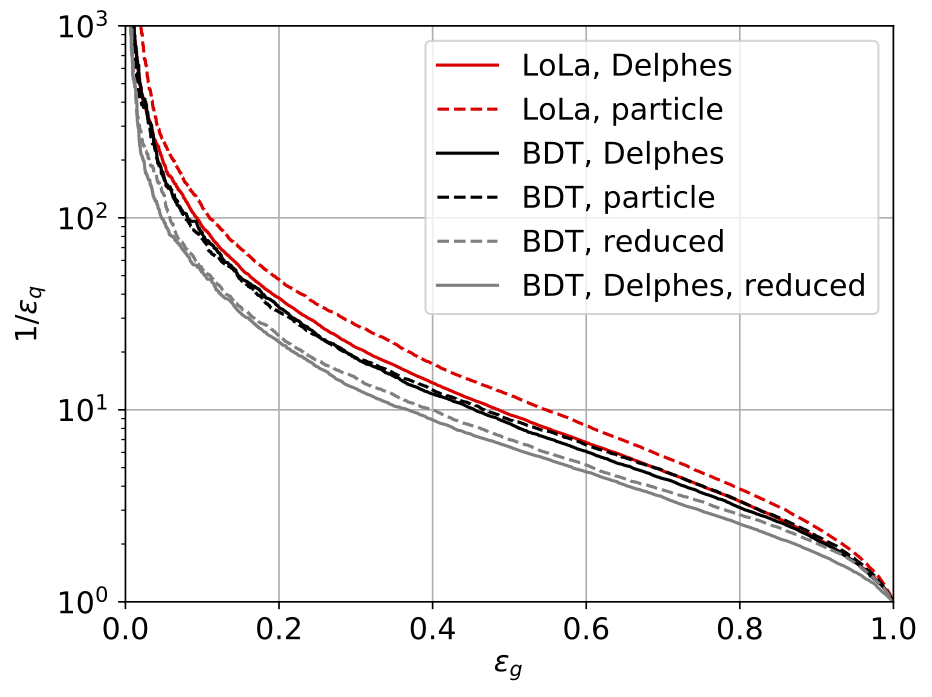 |
Jet autoencoder (2018) based on the DeepTop and LoLa taggers. We show howtop jets are less compressible than QCD jets, how they can be tagged, and how we can de-correlate the jet mass using an adversary. We also test the autoencoder on new physics in jets. |
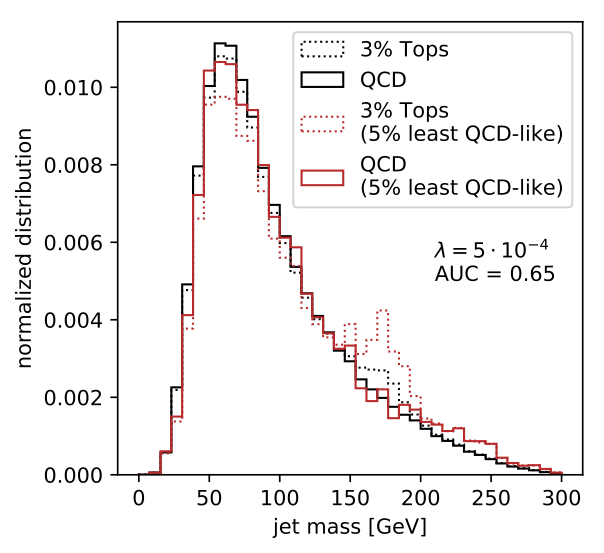 |
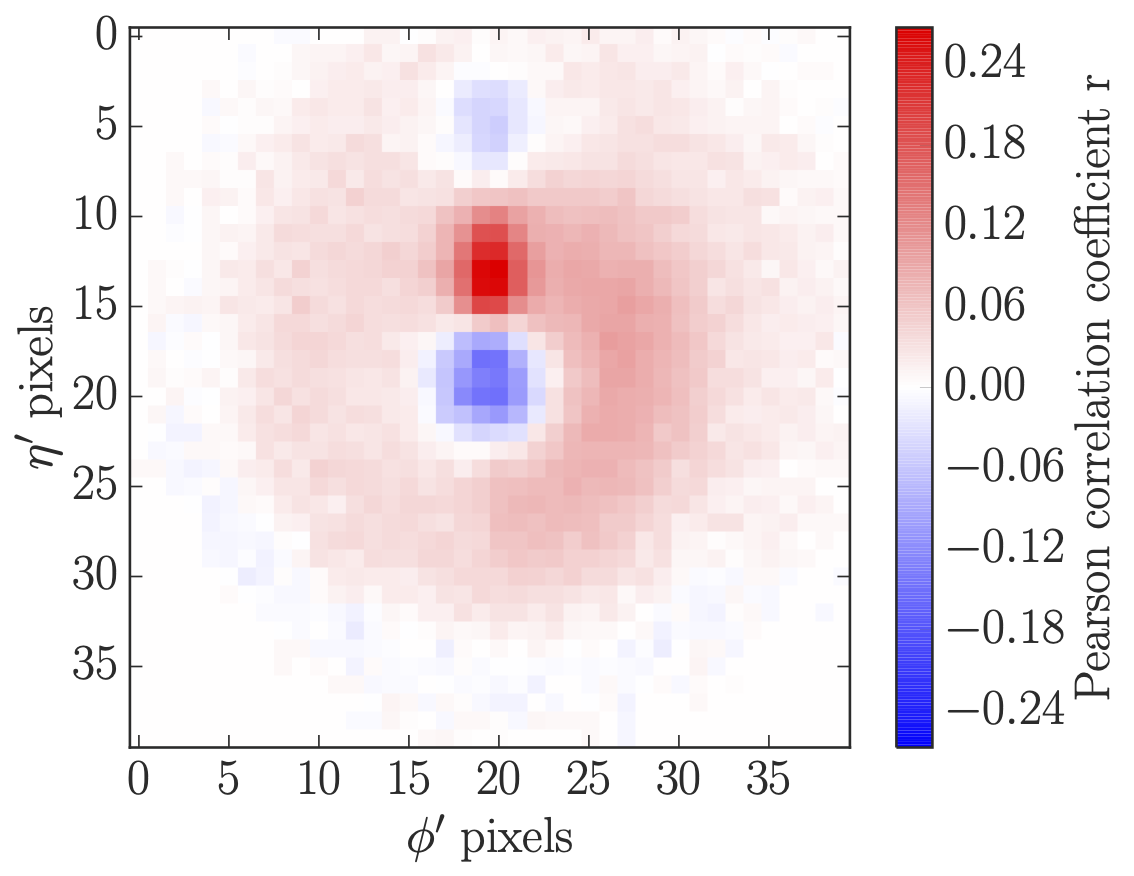
4-vector-based LoLa tagger (2017) which allows us to combine information from the calorimeter and the tracker, accounting for the different resolutions. It can be thought of a graph network over Minkowski space, where we use the fact that we know the Minkowski metric. For a cross check this is one of the few papers which quotes the Minkowski metric with an error bar. |
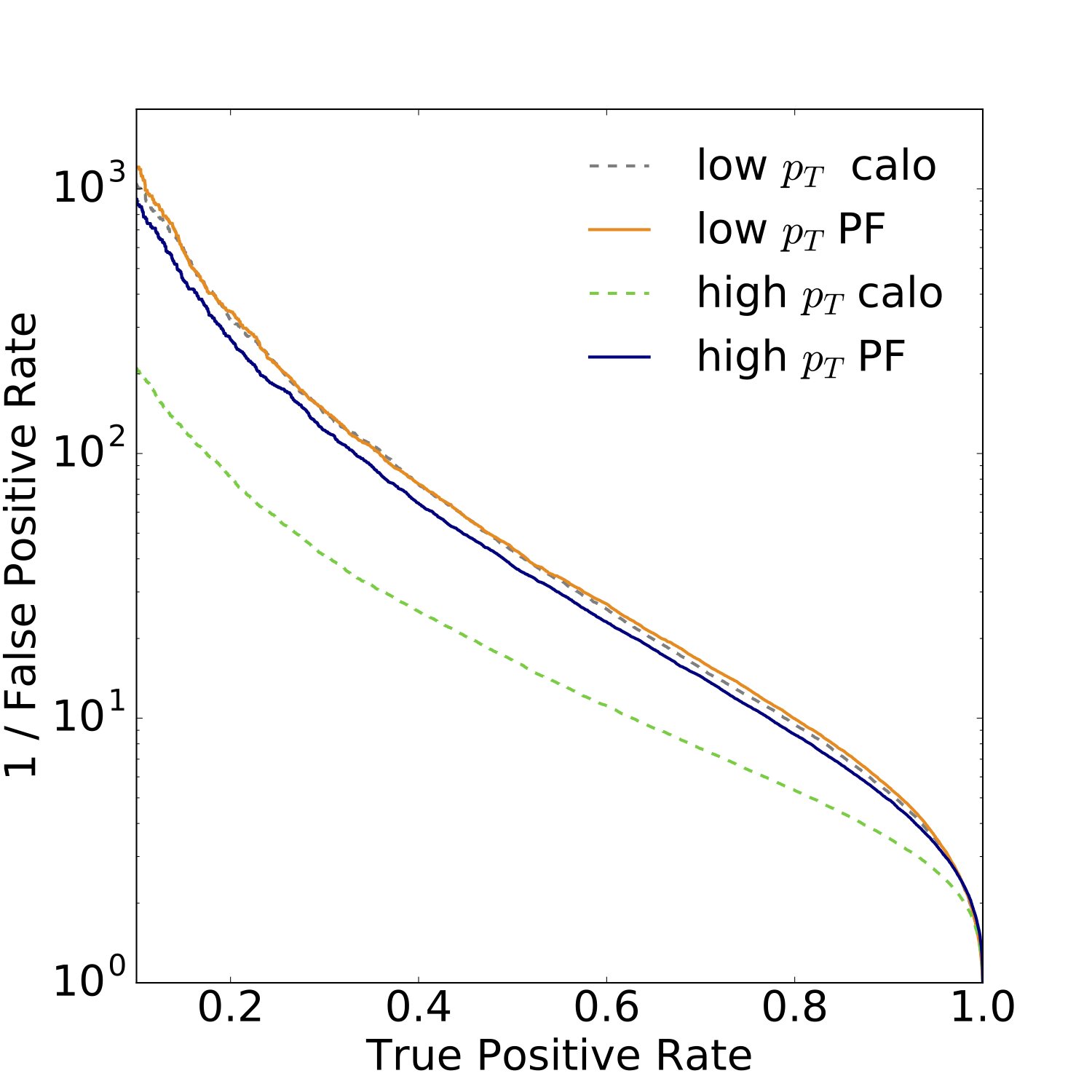 |
Image-based DeepTop tagger (2017) showing that we can use convolutional networks on calorimeter images to identify boosted tops. We showed how this deep-learning tagger compares to classic multi-variate methods and how it is possible to interpret the intermediate layers and the output of the tagging network. |
 |
Event Generation
First-principle simulations LHC events based on quantum field theory (mostly QCD) is one of the unique features of LHC physics. Many groups are investing a huge effort into computing the underlying predictions in perturbative quantum field theory. These prediction can be included in multi-purpose event generators like Pythia, Sherpa, Madgraph, or Herwig. These simulations are based on Monte Carlo simulations and are extremely efficient. The question is if we can use machine learning tools to improve them further or to get access to information that is usually lost in the simulation framework. One example is the use of the hard matrix element in a hypothesis test, usually called the matrix element method. An important part of this research direction is the uncertainty quantification for generative networks. Our group includes Marco Bellagente, Anja Butter, Sascha Diefenbacher, Manuel Haussmann, Theo Heimel, Nathan Hü:tsch, Gregor Kasieczka, Ulli Kothe, Claudius Krause, Michel Luchmann, Jonas Spinner, Sofia Palacios Schweitzer, Armand Rousselot, and Ramon Winterhalder, and it is still expanding.
Detector simulations rely on the same kind of generative networks as LHC event generation, but with a much higher-dimensional phase space (2023). For the ML4Jets calorimeter challenge we show how normalizing flows can be pushed towards higher-dimensional phase spaces, where they are not as expressive as modern diffusion networks, but extremely fast. |
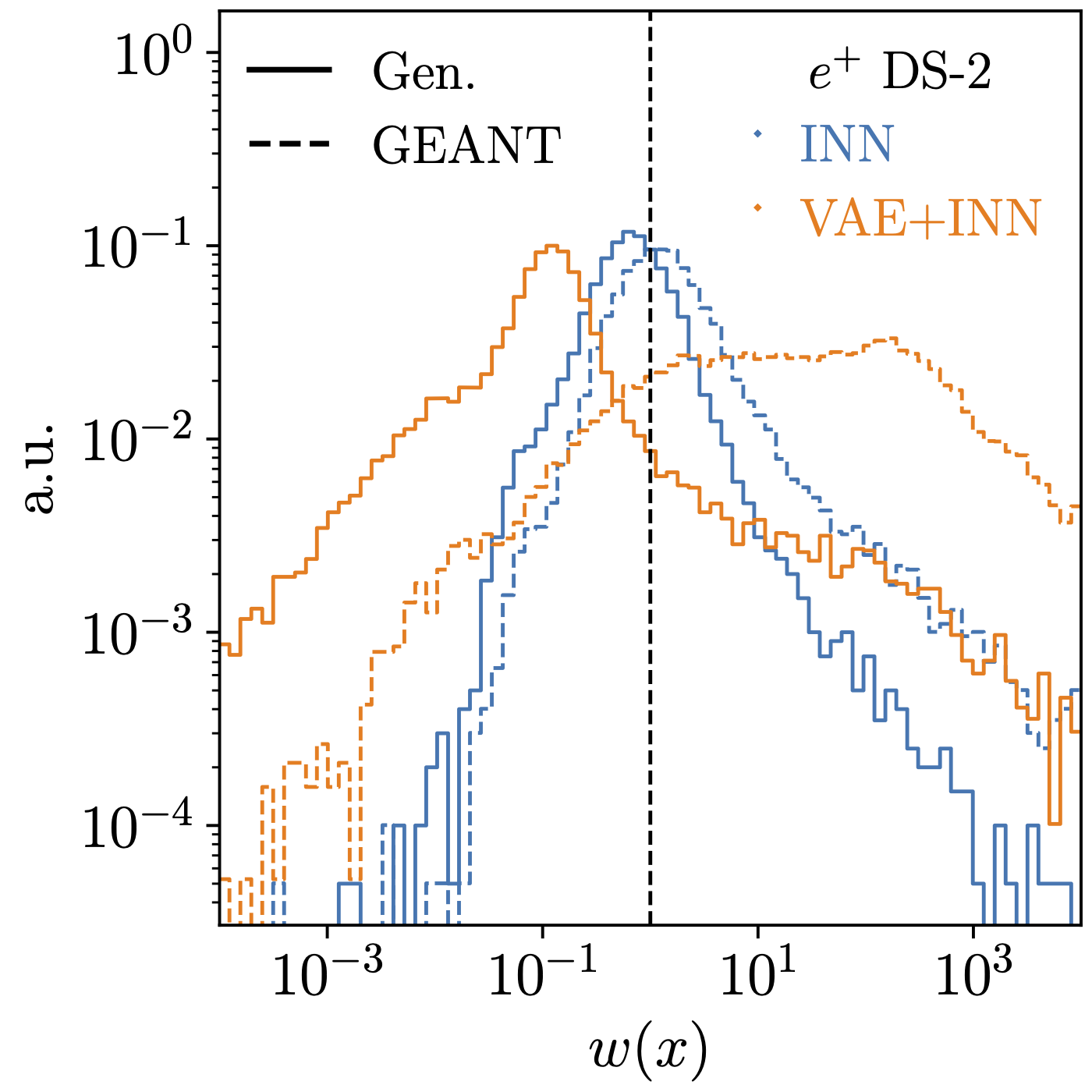 |
Generating event samples from other event sample can be done using direct diffusion, based on conditional flow matching networks (2023). We use this novel method to generate off-shell top pair events from on-shell top pair events, enlarging the starting phase space while retaining the original correlations to much higher precision than a training from scratch would normally achieve. |
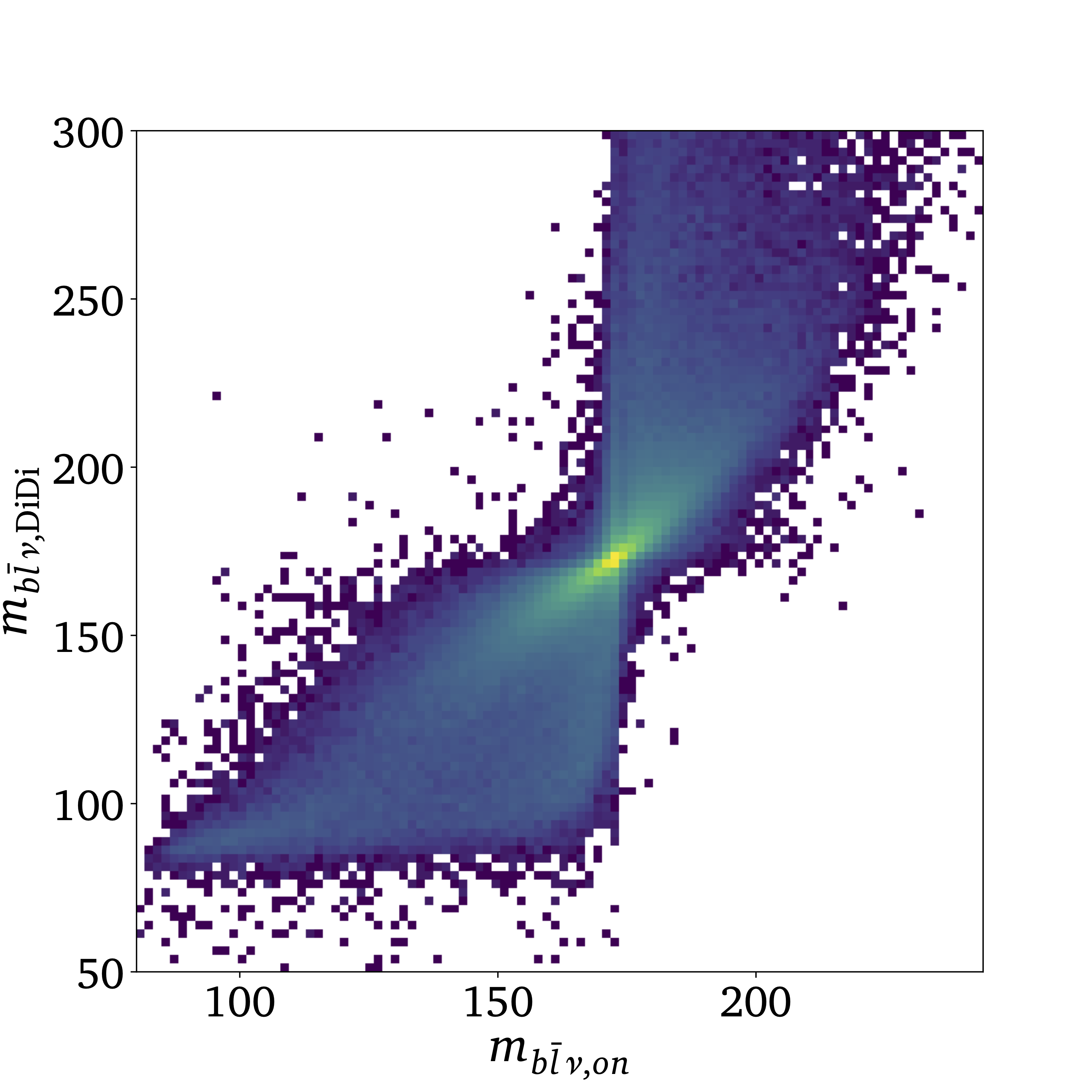 |
To become a part of the next Madgraph generator, MadNIS had to be further developed and benchmarked for cutting-edge LHC processes (2023). We significantly upgrade the original MadNIS with a combined online and buffered training, VEGAS pretraining, and many other features. For complex processes, it outperforms the current Madgraph phase space sampling significantly. |
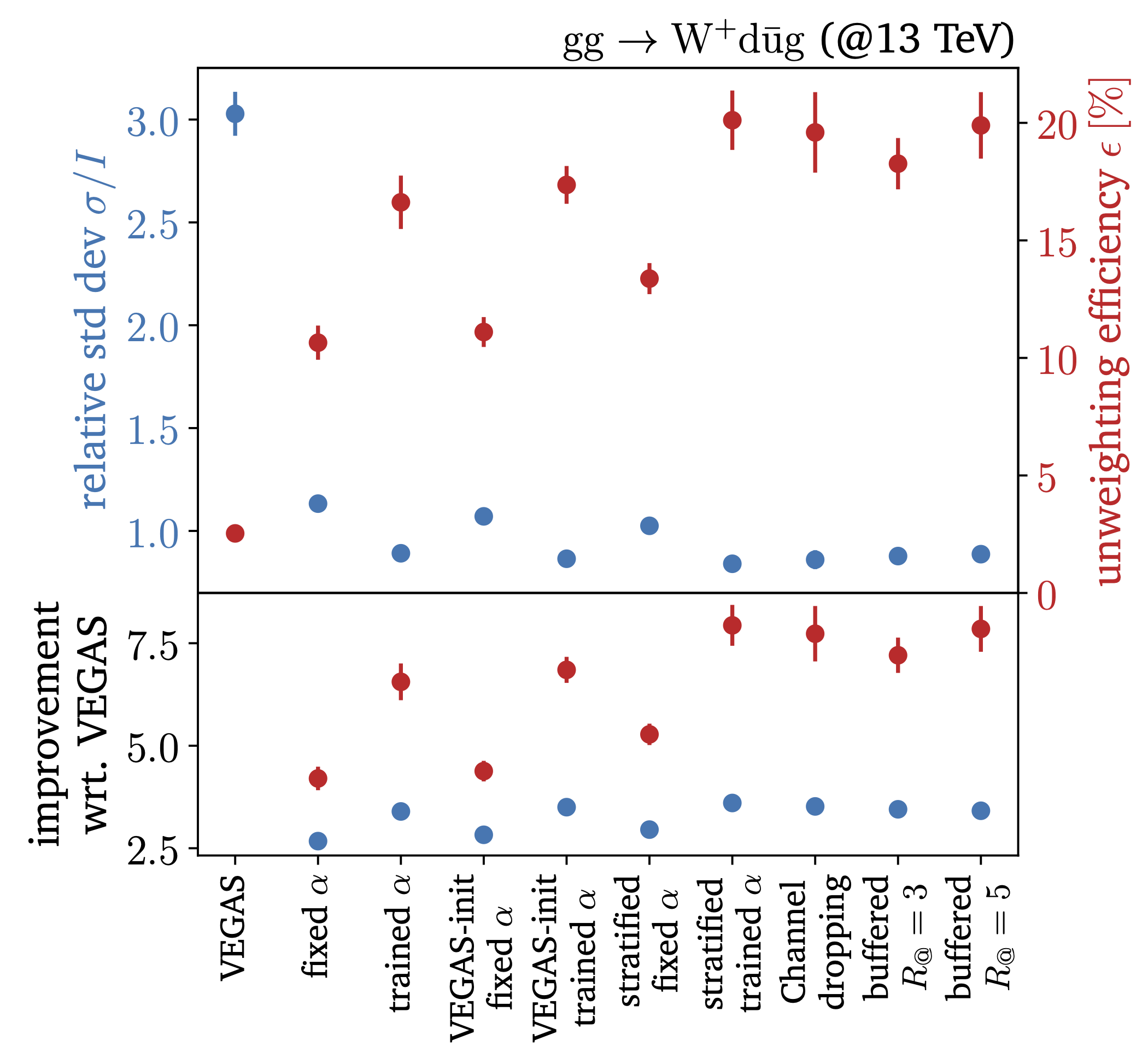 |
How can we test the precision of generative networks for the LHC (2023)? This question is at the heart of all LHC applications, and we show how trained classifier weights allow us to systematically control the generative network performance over the target phase space. We show this for generated jets, calorimeter showers, and LHC events. |
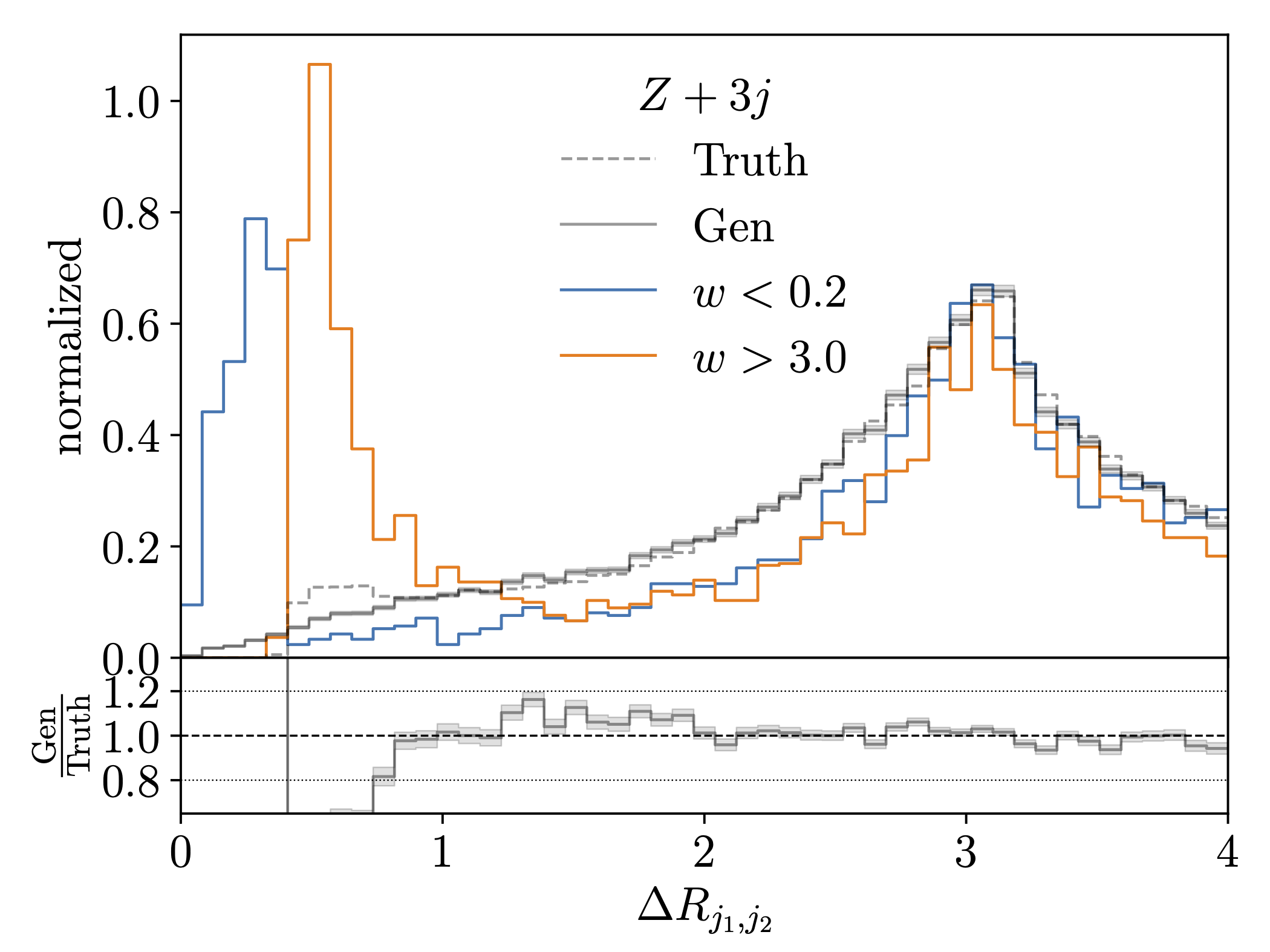 |
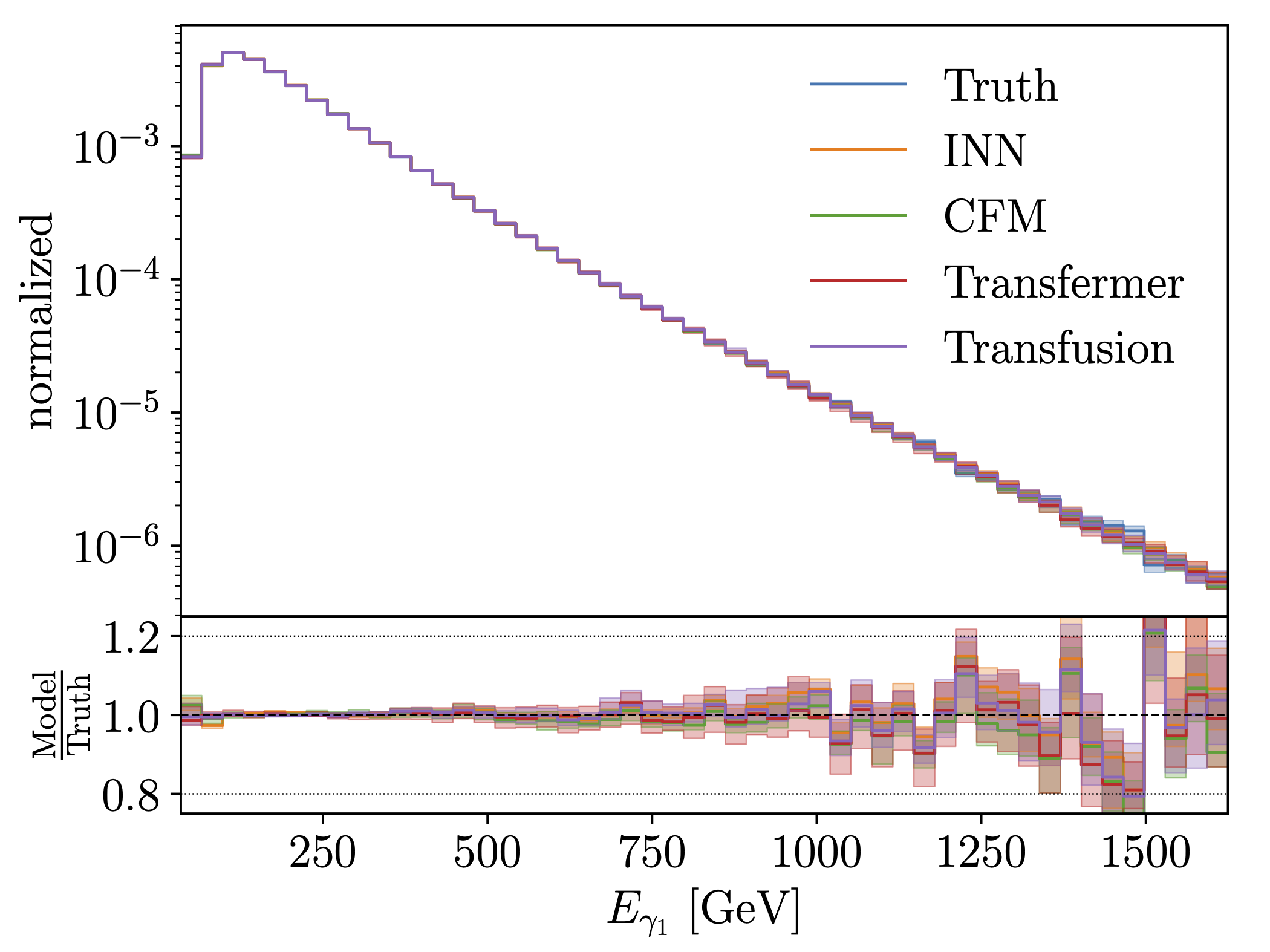
Modern generative networks which can be used for LHC simulations include so-called diffusion networks and autoregressive transformers (2023). Indeed, we find that while DDPMs are not significantly better than normalizing flows with coupling layers, conditional flow matching should replace normalizing flows whenever we do not need an invertible networks. Autoregressive transformers, Jet GPT, are extremely promising as well, but require a little more work on their controlled precision. |
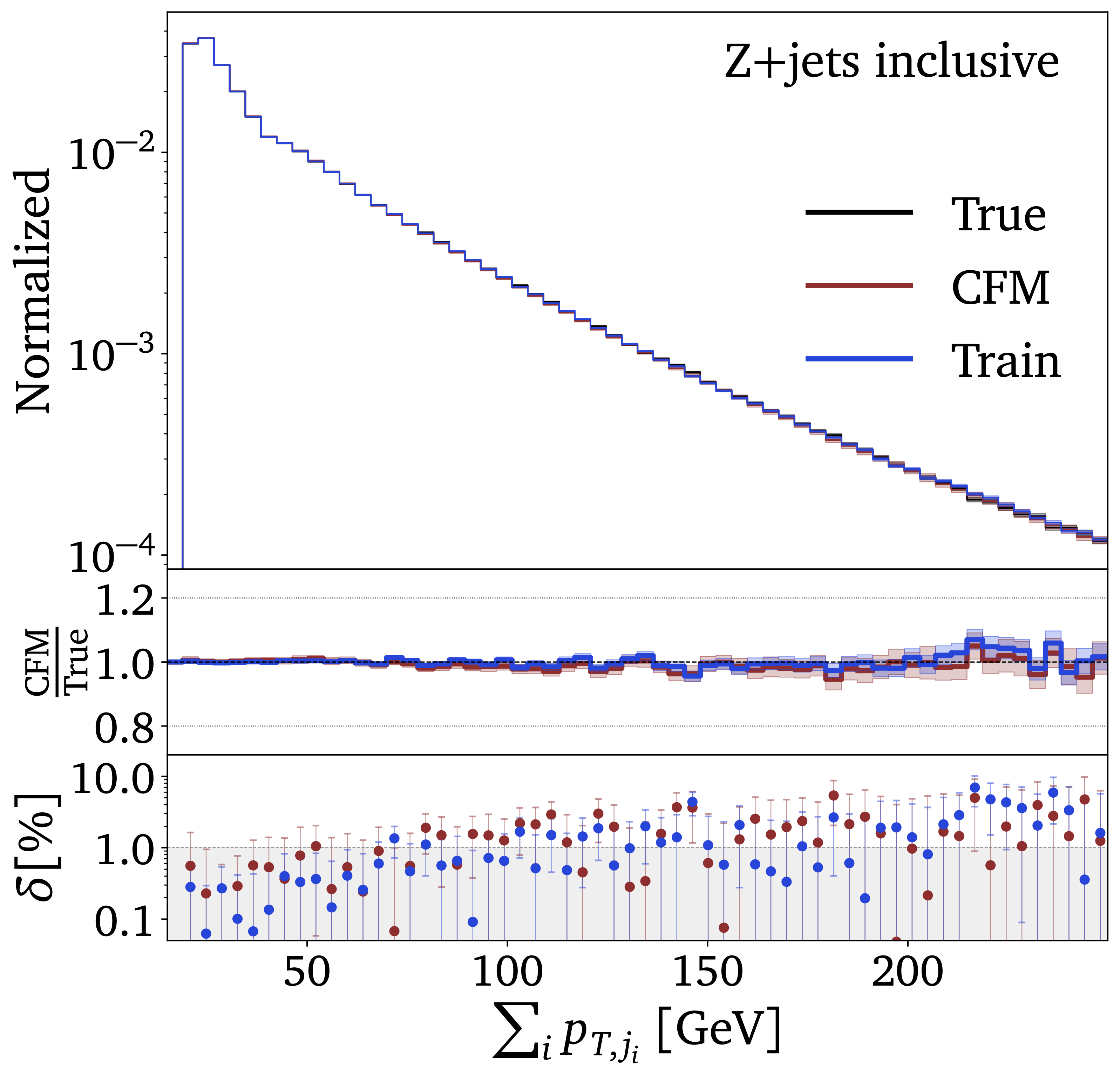 |
MadNIS is an ML-based multi-channel importance sampling tool for LHC simulations (2022). It replaces learned channel weights with locally defined regression networks and importance sampling with an INN or normalizing flow. Key to an efficient training of the two networks is the combination of online training and buffered training, making optimal use of expensive integrands. In the appendix we discuss a whole range of possible loss functions for this bi-directional training. |
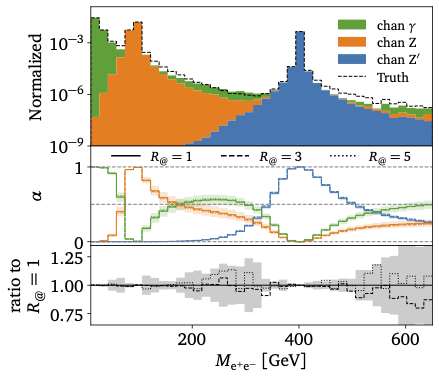 |
Precision network setup based on Bayesian networks combined with a boosted training for LHC amplitudes (2022). One challenge for precision networks is that neural networks can be too powerful in fitting through key regions of phase space. In this situation it would be beneficial to interpolate through some training data points rather than fit a function over the full phase space. We use a Bayesian network to decide which training data points are not reproduced well enough and re-weight these data points in the likelihood loss. |
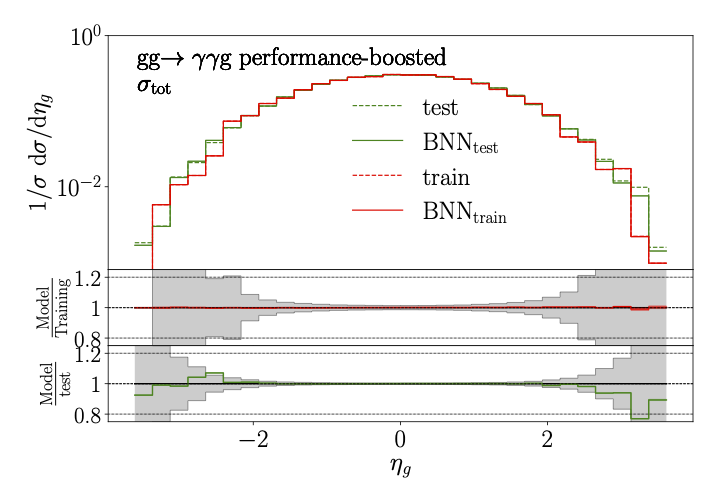 |
Community report and review article on machine learning applications in LHC event generation (2022). The report started as a contribution to the US Snowmass process and turned into a detailed description of the state of the art in machine learning for event generators. It includes ML-applications to standard generators, soup-to-nuts ML-generators, and different approaches to unfolding and inference. |
 |
Proposal to use a generative network to supplement the data-scouting trigger (2022). The idea is to train a generative network on LHC data which does not pass the standard triggers and compress the incoming dataset instead of compressing individual LHC events. We compare the discovery potential of such a generative network with the corresponding data-scouting performance or trigger-lwevel analysis. It turns out that compressing data samples is actually more efficient than reading out a fraction of events using comparable bandwidth. |
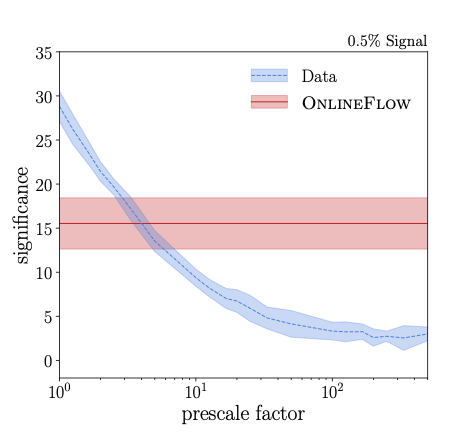 |
First proof that amplification by generative networks works for a detector simulations (Calomplification) in a semi-realistic setup (2022). For photon showers in an electromagnetic calorimeter we show that generative models outperform their training dataset statistically by using an implicit bias adapted to the phase space density expected for such a physical process. |
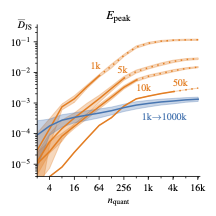 |
As a side project, the first application of machine learning to loop integrals, (2021). We use a normalizing flow network to describe a contour integration for different 2-loop integrals with several mass scales. The network is trained to construct the optimal integration path for the Feynman parameters. |
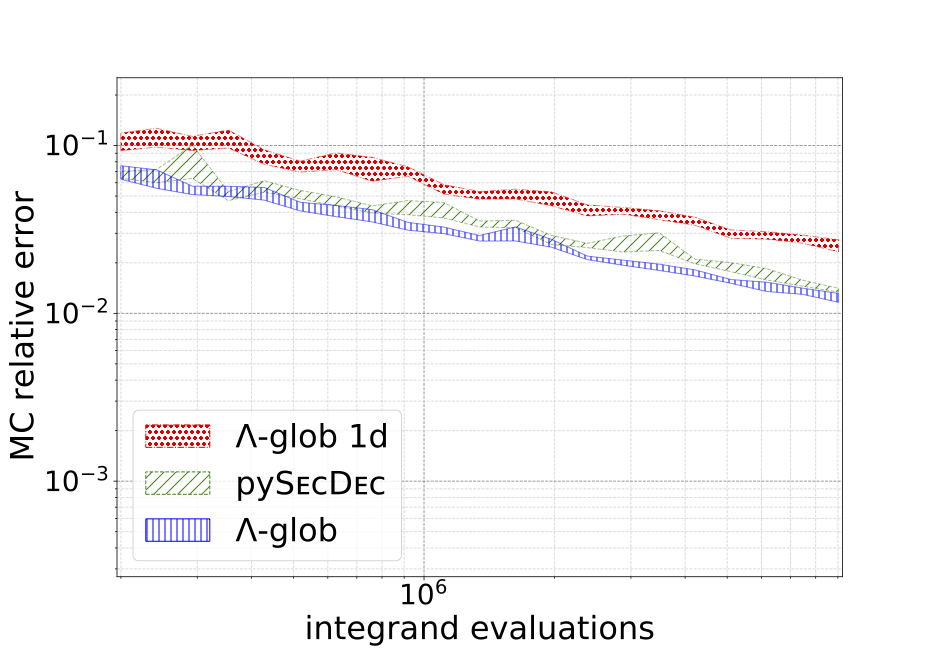 |
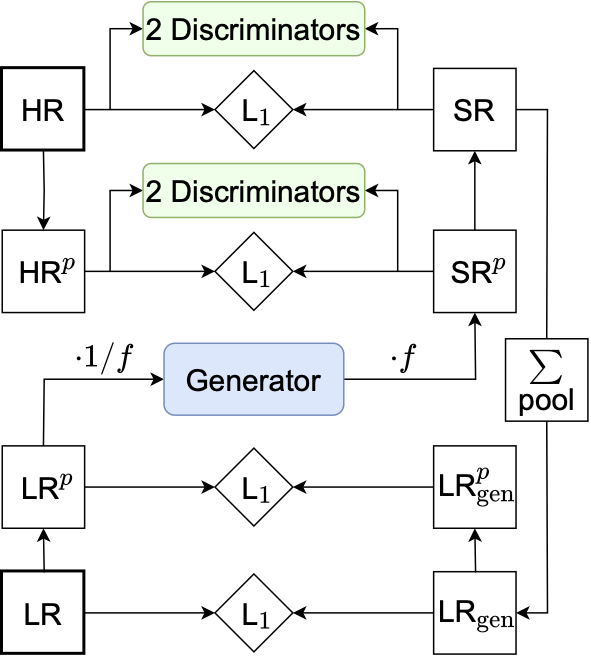
The first application of a Bayesian precision generator, to LHC event generation (2021). It combines an INN-normalizing flow generator with a discriminator for reweighting and for a combined, GAN-like training. The generator-discriminator coupling follows an alternative approach to the usual adversarial training. Training-related uncertainties are described through a Bayesian network, systematic uncertainties through conditional training. |
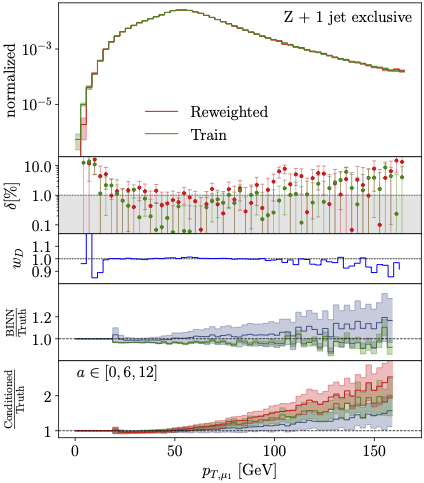 |
Brand-new Bayesian generative network, specifically a normalizing flow network or INN (2021). It learns not only a density map over phase space, but also an uncertainty map, and it provides this information in terms of events with an uncertainty weight. That setup is probably the first time, someone has attached uncertainties to a generative network, a crucial step for LHC applications. Moreover, we can study how the network learns the density and uncertainty maps in parallel and confirm that the flow network really works like some kind of functional fit. |
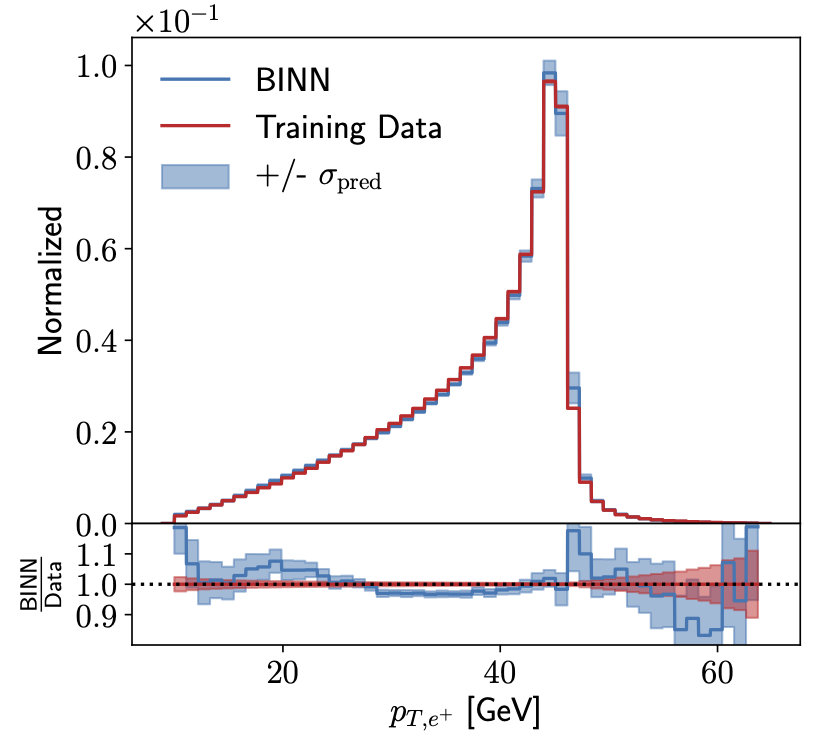 |
Study of super-resolution on jet images (2020). The mis-match of calorimeter and tracking resolution on jet constituents is one of the leading themes of jet classification. We show how this measurement structure motivates applying a generative super-resolution network. As usual, we look at QCD vs top-decay jets and study the model dependence for these two kinds of jets. |
 |
GAN study on event unweighting (2020). The transformation of weighted events into unweighted events is the numerical bottleneck of many LHC simulations. We show how the classic hit-and-miss algorithm can be improved significantly by applying a generative network which gets trained on weighted events and produces unweighted events. |
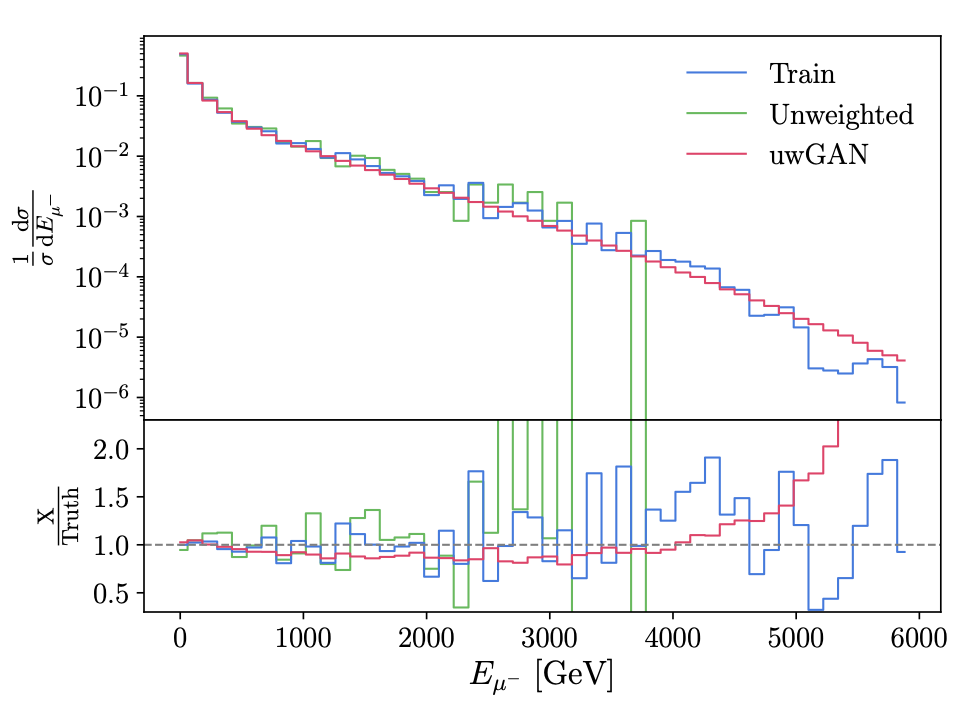 |
Generative networks review article (2020). We given an overview of the many ways generative networks are developed for LHC event generation. This includes many different architectures and applications. |
 |
GAN study on the statistical gain (2020). An open question, crucial to LHC applications, is how much we can gain beyond the statistical power of the training sample by training a generatve network for more events. We define an amplification factor for simple multi-dimensional toy distributions and first find that, just like a fit, the structure of the GAN adds information to the discrete set of training events. Second, the GANned events do not have the same individual statistical power as a sampled event. The GAN applification factor becomes larger for sparcely distributed training data in high-dimensional phase spaces. |
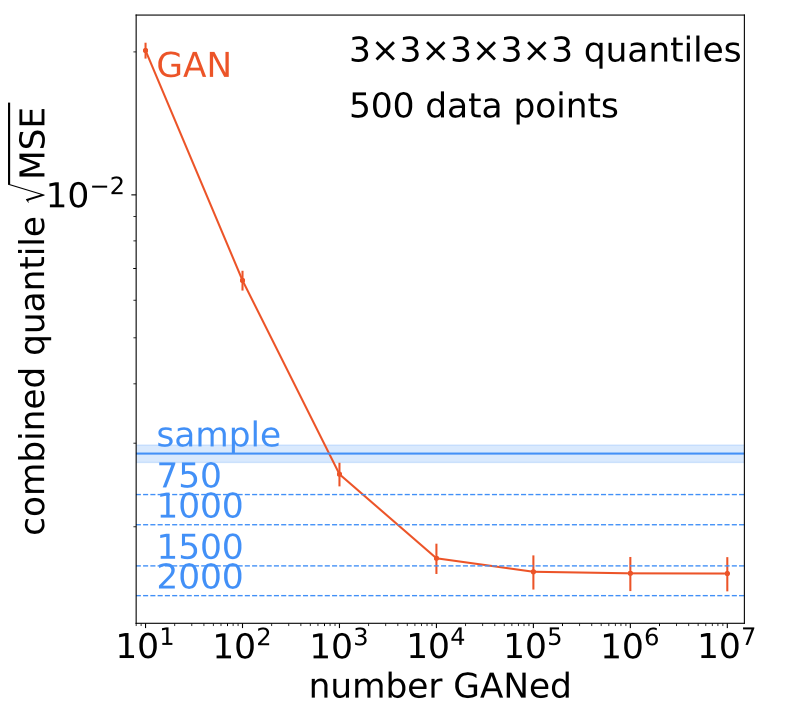 |
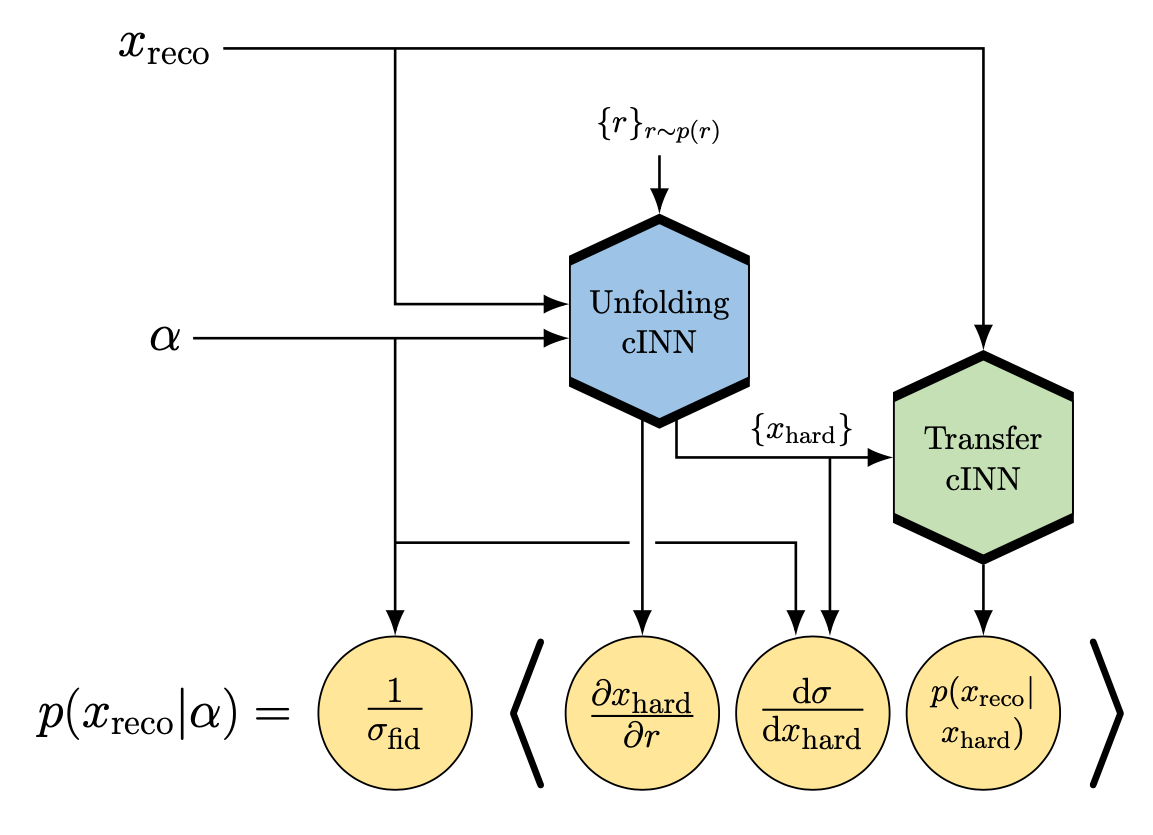
Conditional INN application to detector and QCD unfolding (2020). Invertible networks based on normalizing flows and built out of coupling layers can also serve as generative networks for LHC events. Their greatest advantage is that in a conditional setup they are built to generate spread-out probability distributions in the target space. For LHC unfolding this means we can construct a probability distribution over parton-level phase space for a single detector-level event. We expand the detector unfolding to also unfold jet radiation to a pre-defined hard process. |
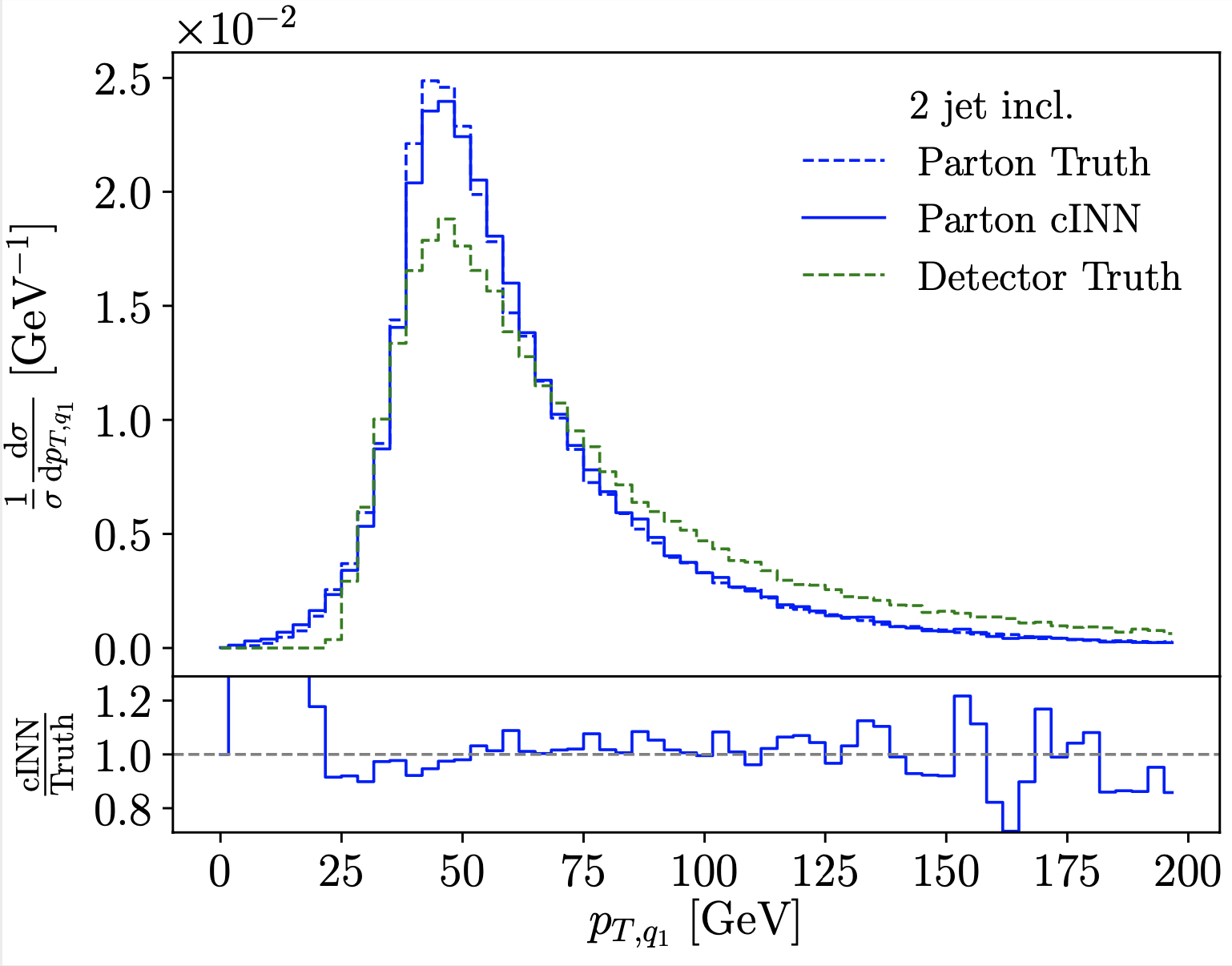 |
Fully conditional GAN application to detector unfolding (2019). If we train a conditional GAN on matched event samples we can use it to invert a Monte-Carlo-based simulation of, for instance, detector effects. This unfolding is not limited to one- or low-dimensional distribution, but covers the entire phase space. The matching of local structures in the two data sets reduces the model dependence of the unfolding procedure. |
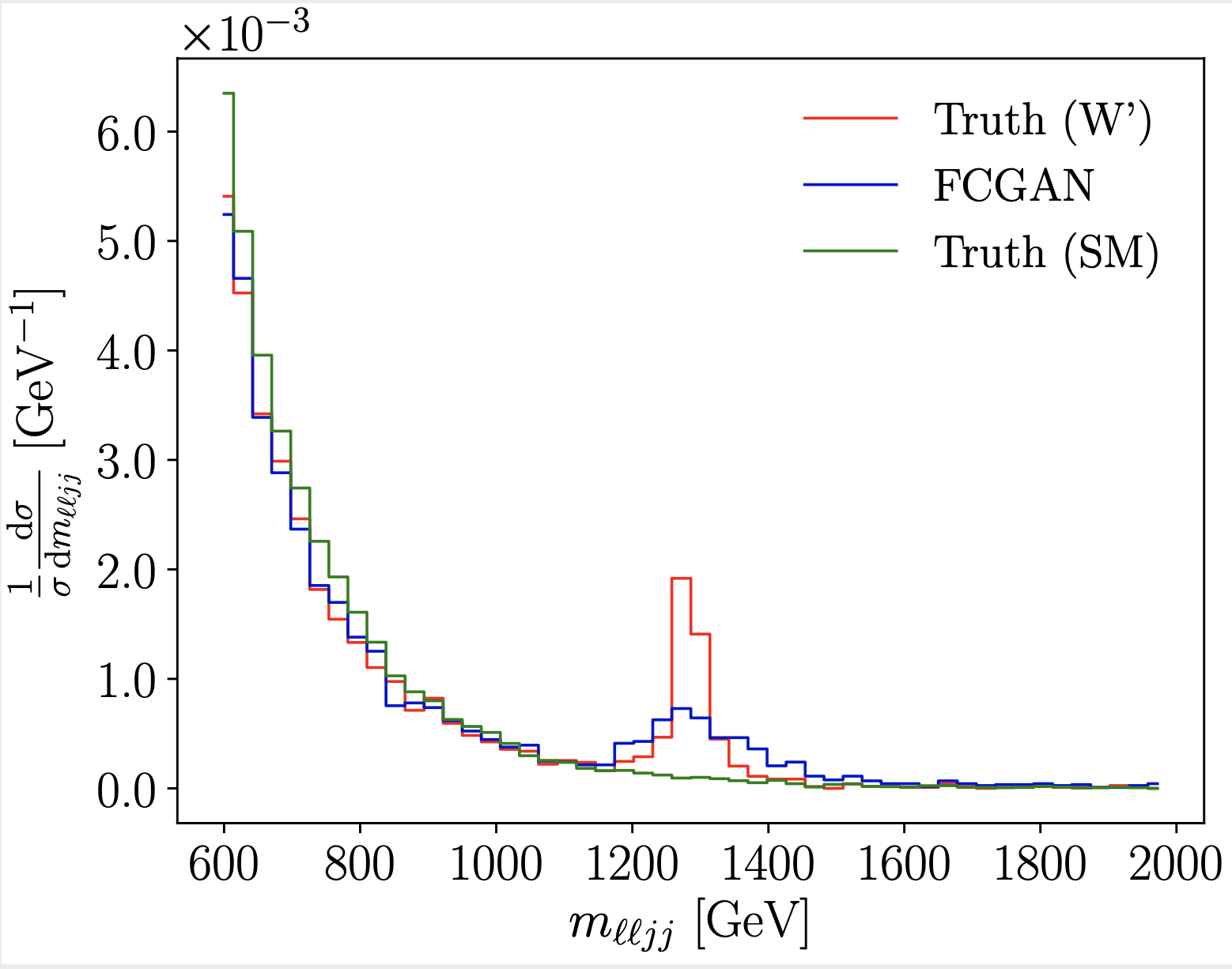 |
GAN application to event subtraction (2019). A general problem in dealing with event samples is that there is no efficient way to subtract event sample from each other, or combine events with positive and negative weights. We show how GANs can do that avoid statistical limitations from the usual binning procedure. Applications could be subtraction terms in Monte Carlo simulations or background subtraction in analyses. |
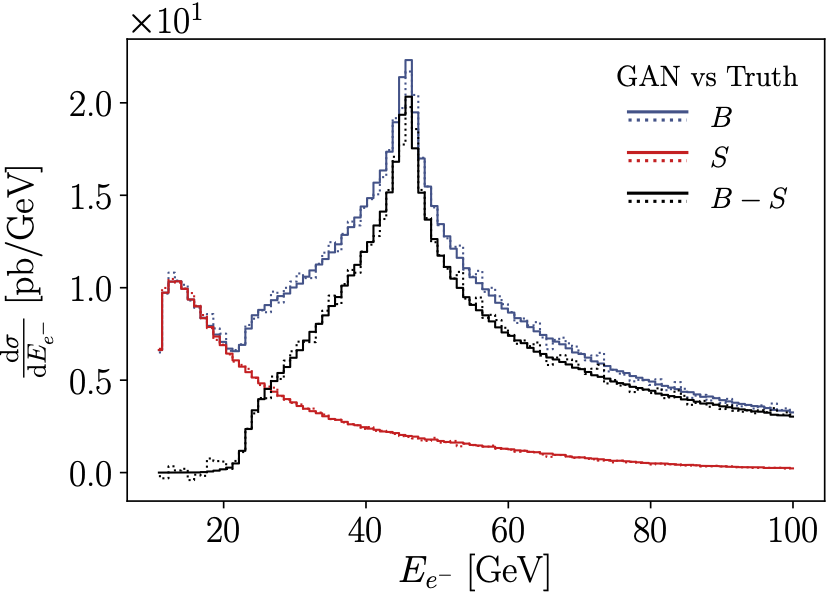 |
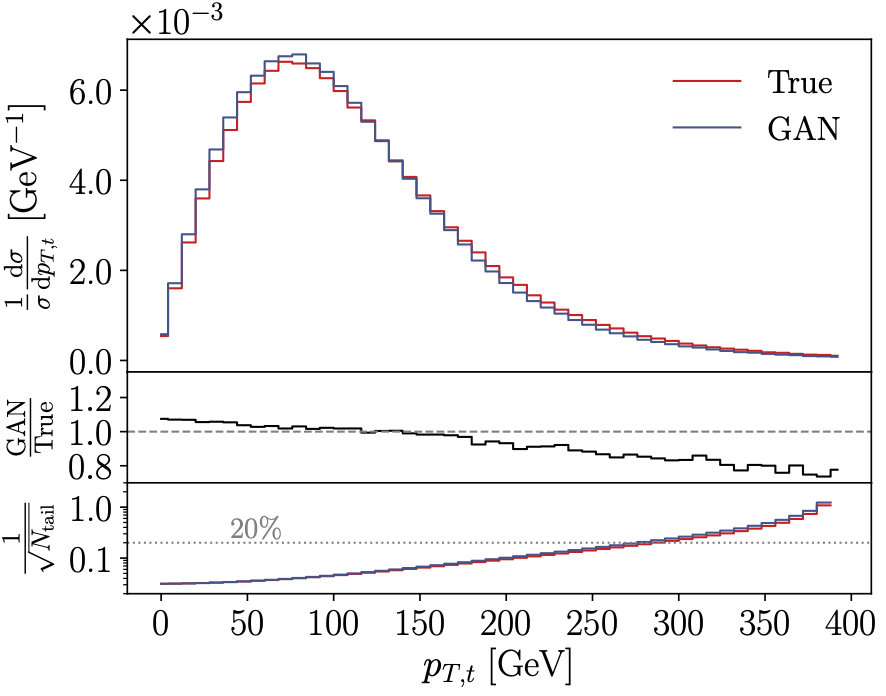
GAN application to event generation (2019). We show that a GAN, supplemented with a dedicated MMD loss, can generate top pair production events at the LHC. We model all kinematic distributions all the way to the three top decay jets. We find that regions with large systematic uncertainties on the GAN are directly linked to sparse training data. |
 |
Inference
Finally, LHC measurements can benefit conceptionally from machine learning methods. To start with, information geometry is not exactly machine learning, but it is a concept which benefits from machine learning when we apply it to LHC physics. The question we are trying to answer is what kind of information is available to an LHC analysis, what observables capture it best, and what the limiting factors in an analysis might be. The machine learning aspect only comes in once we ask these questions beyond the parton level, and two former Heidelberg students (Johann Brehmer and Felix Kling) have worked with Kyle Cranmer's NYU group on developing the corresponding MadMiner program. Other collaborators on this topic include Sally Dawson and Sam Homiller for Higgs applications, or Ulli Kothe and Stefan Radev for invertible networks. In the Heidelberg group, inference methods related to Madgraph are being developed by Ramon Winterhalder and Theo Heimel, with the help of Nathan Hütsch. Applications in cosmology are based on a collaboration with Caroline Heneka and her group, for example Benjamin Schosser.
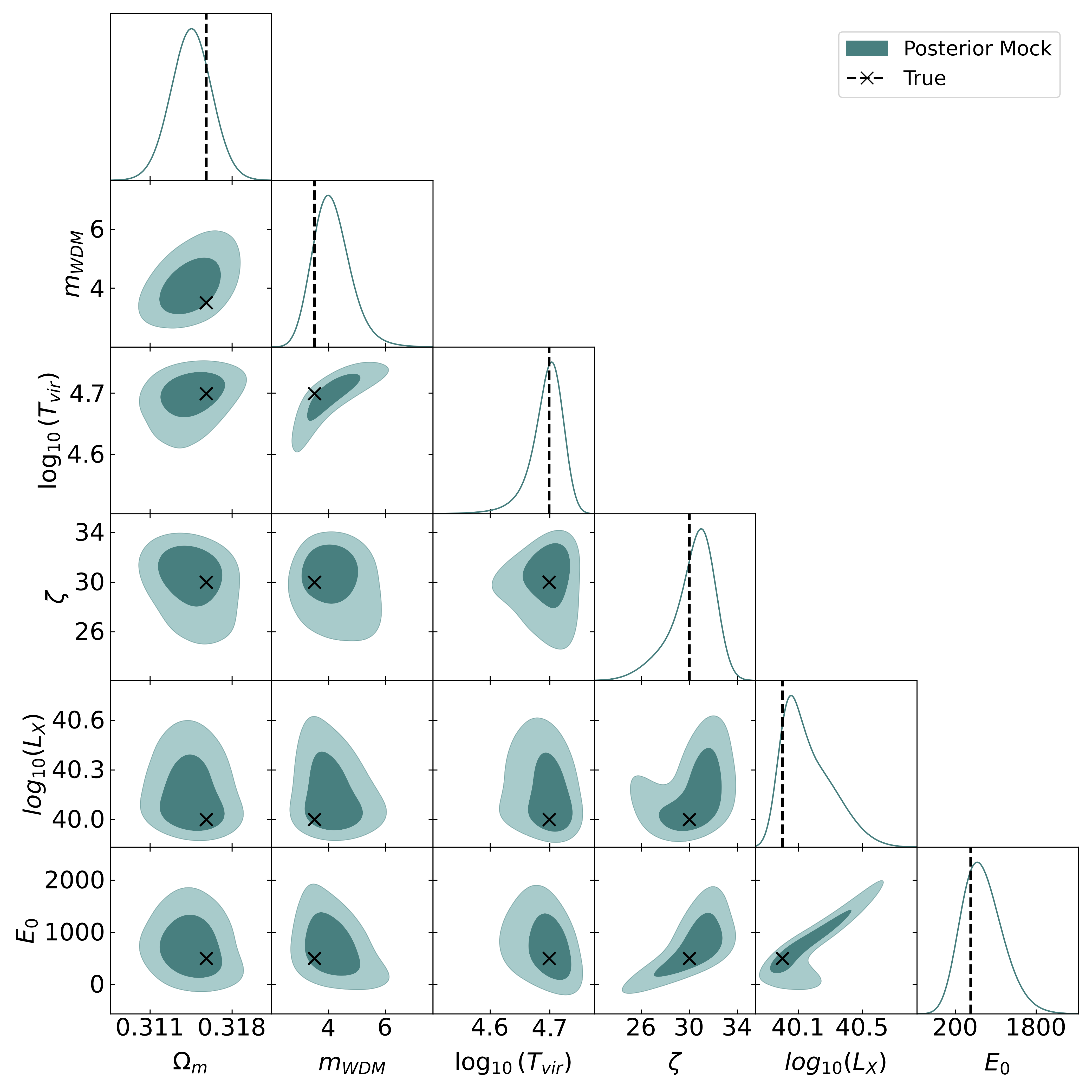
Using conditional generative networks for 21cm cosmology inference is, technically, very similar to LHC inference (2023). Interestingly, we can use a summary network especially designed for the complex structure of future SKA data to extract cosmological parameters with a fairly simple conditional generative network. |
 |
To tackle the challenges from our first study of ML-driven improved matrix element method we develop and benchmark a more sophisticated setup (2023). This includes a classifier-based efficiency network and a transformer pre-processing to solve the combinatorics. This three-network architecture should allow us to use this optimal inference method at the LHC. |
 |
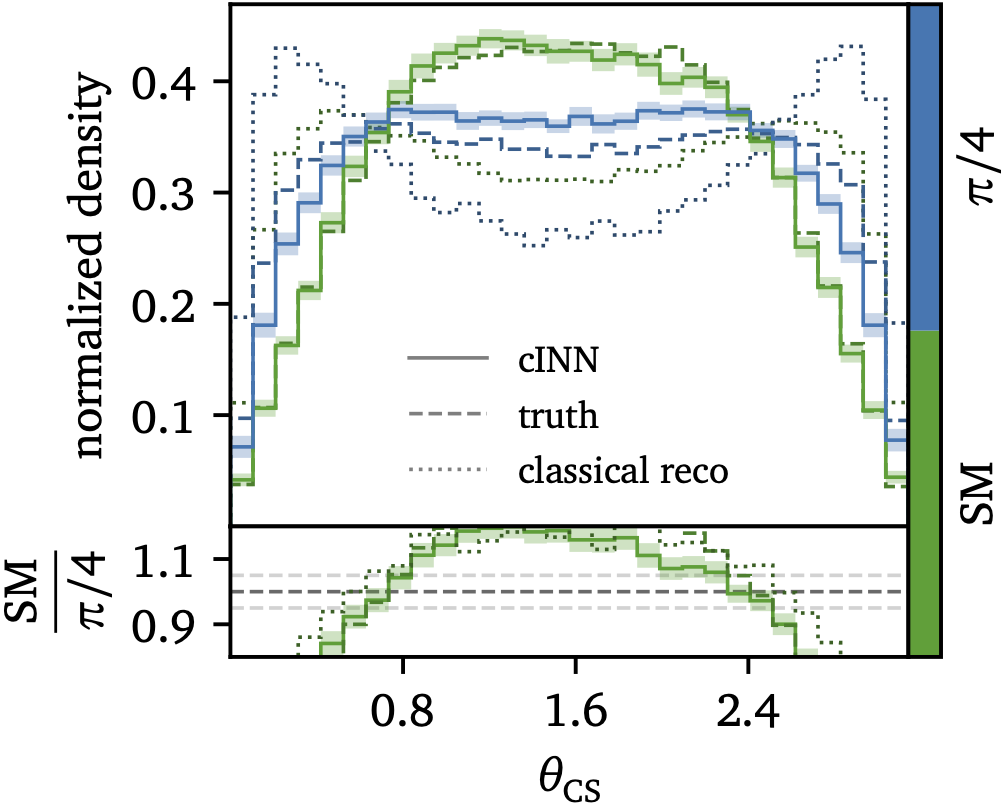
A simple application of unfolding is are network-defined observables, for instance using the same conditional generative networks used for full-dimensional event unfolding (2023). This method allows us to encode, for instance, optimal observables for CP-violation of powerful observables like the Collins-Soper angle, which usually require a complex kinematic algorithm as part of their reconstruction. |
 |
First attempt to enhance the matrix element method with generative networks (2022). To extract a fundamental parameter from individual events or small samples, the so-called matrix element method has been developed at the Tevatron. The challenge of this method is phase space sampling for general transfer functions, which can be solved by combining two normalizing flows, one describing the transfer function and one for the phase space mapping. |
 |
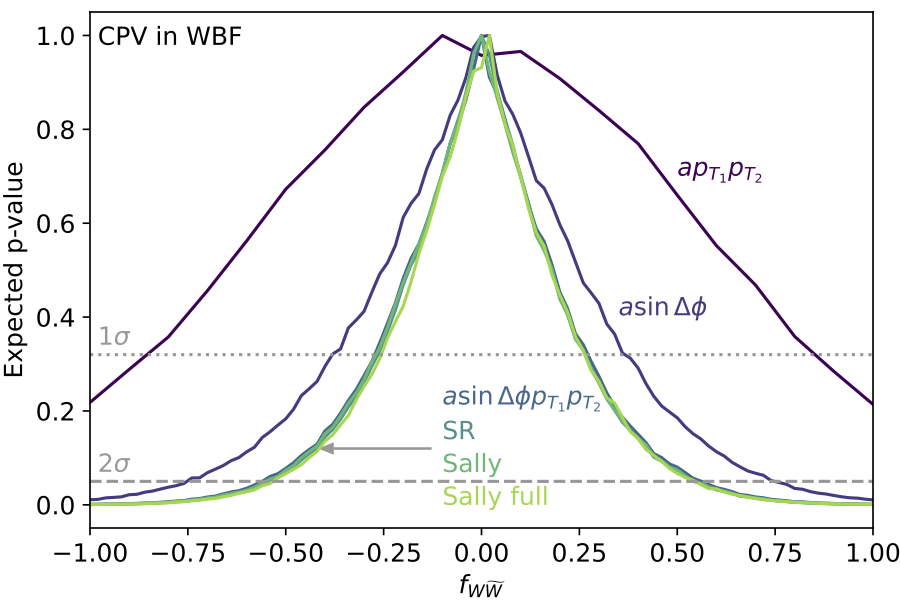
First application of symbolic regression to LHC physics (2021). We compute the optimal observable or score for extracting certain higher-dimensional operators from LHC events. Formulas are extracted from standard simulated data sets, where we use MadMiner to compute the score and a slightly modified version of PySR to find appropriate formulas. We test our approach for a simple ZH production toy model in detail and then show how it finds the correct result for CP-violation in weak boson fusion. |
 |
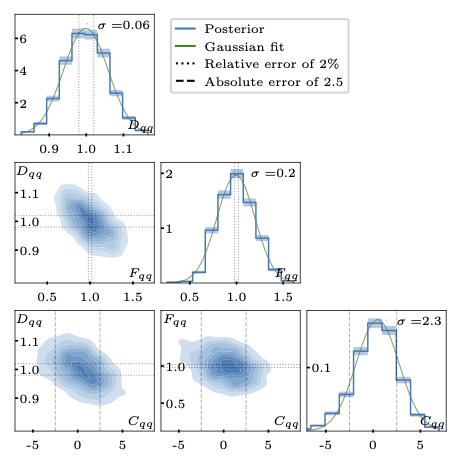
Proposing a measurement of QCD splitting kernels using a conditional INN (2020). We start by defining a new interpretation framework for QCD jet measurements, leading to an actual measurement of QCD-parameters. The complexity of low-level data and the highly non-linear relation between splitting kernels and jet data make this measurement an excellent case for a machine learning application. |
 |
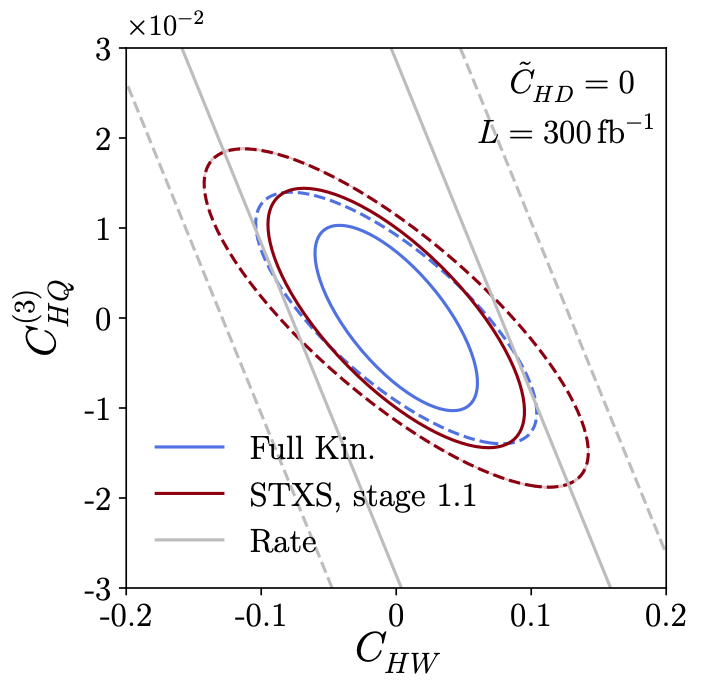
Validation of simplfied template cross sections for VH production (2019). We analyse how these observables compare to an analysis of the full phase space, including detector effects and mixxing transverse momentum. This is where machine learning enters. |
 |
Information geometry of Higgs CP in the SMEFT framework (2017). We compare different Higgs production and decay signatures, all based on the amplitude with four additional fermions, in their potential to test the CP properties of the Higgs coupling to intermediate gauge bosons. We link this approach to the established optimal observables. |
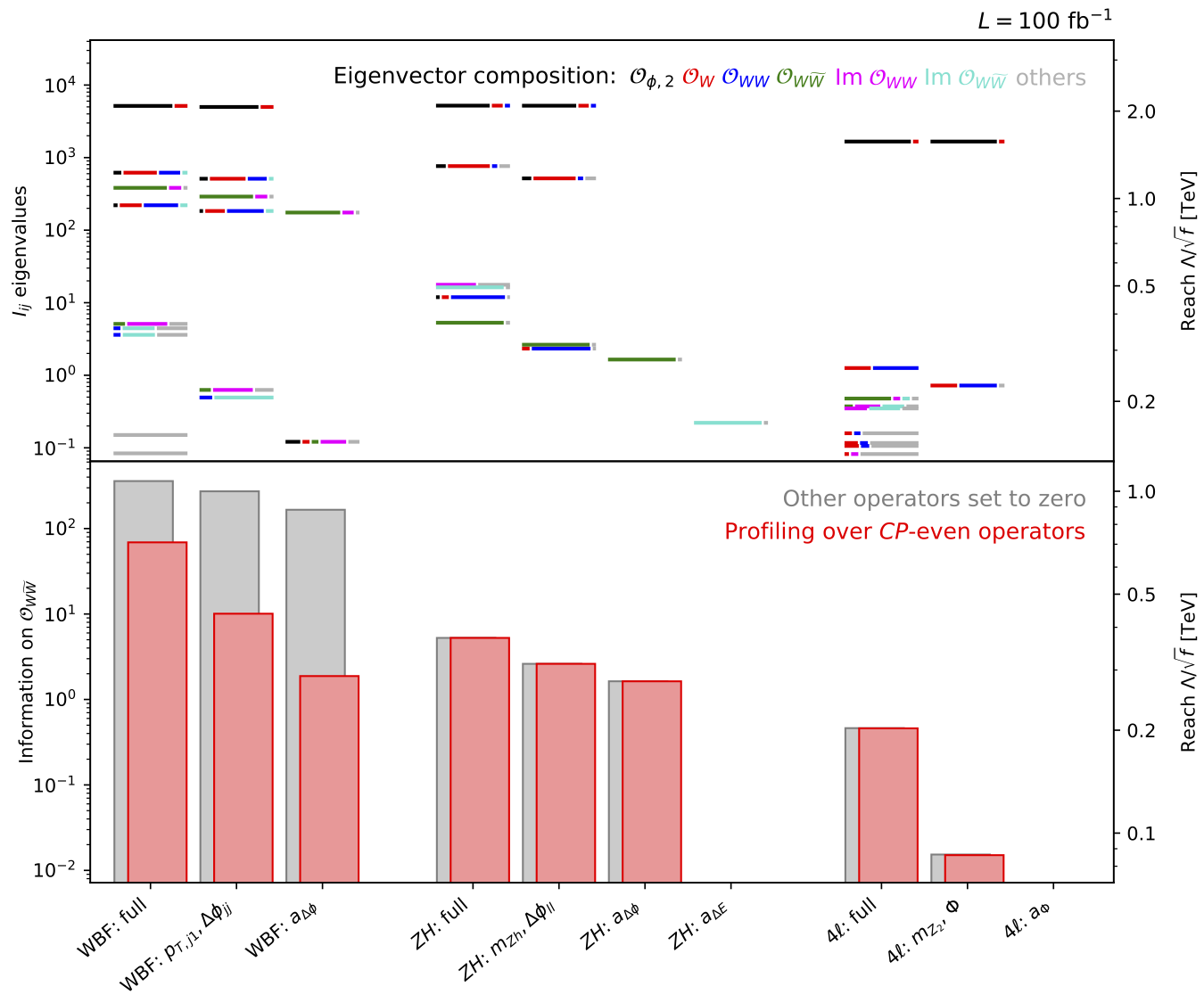 |
Information geometry of Higgs signatures in the SMEFT framework (2016). We compute the information available over the entire partonic phase space of Higgs signatures and compare for instance the impact of the QBF tagging jet kinematics with the Higgs decay kinematics. |
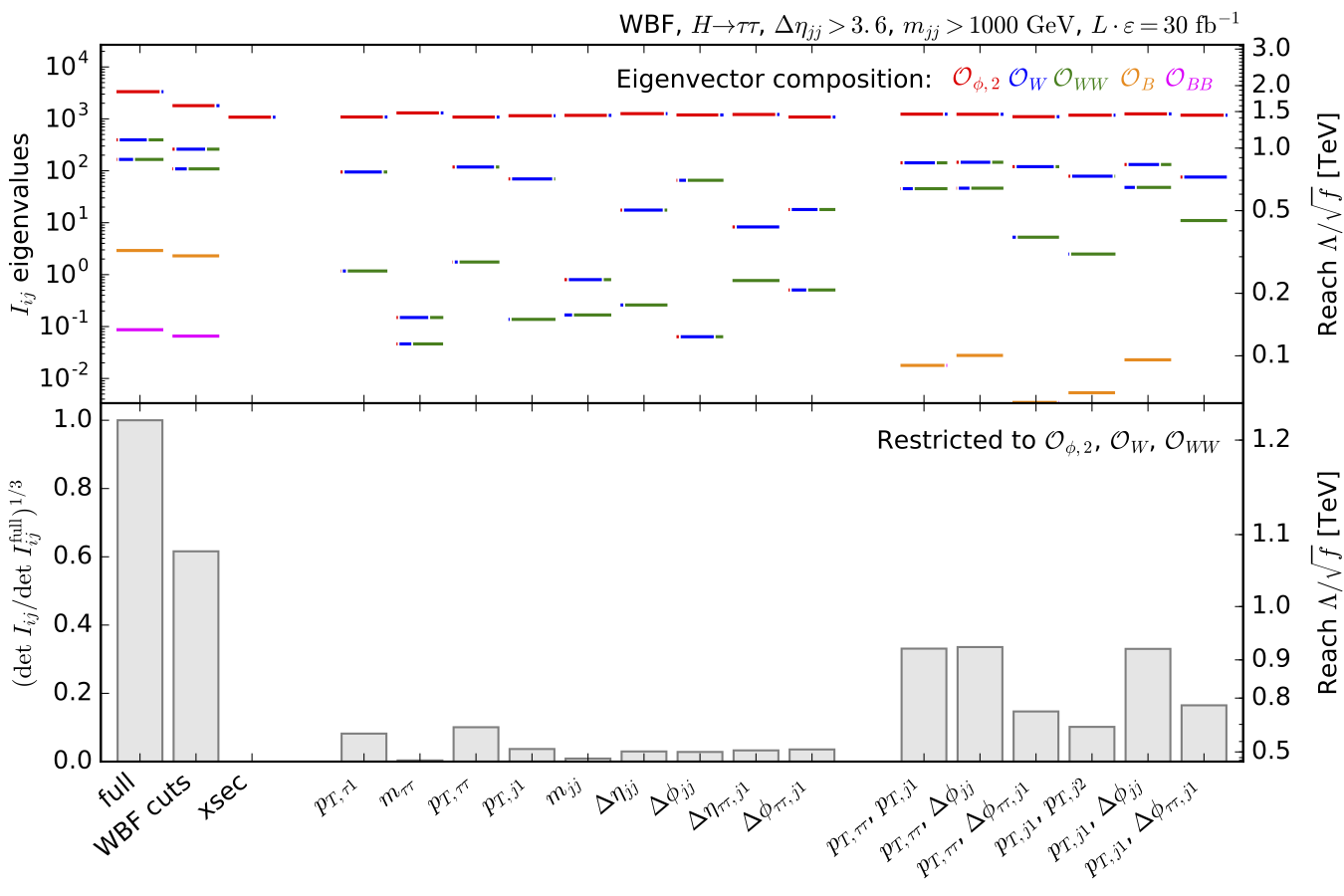 |
Global SFitter analyses
Obviously, machine learning should be able to improve global analyses of LHC data, where we interpret a large number of measurements in a high-dimensional parameter space. Our SFitter tool has serves us well in the last 10 years, so we are working on improving it with machine learning applications. New developments , related to data science, are now being included, with the help of Nina Elmer, Maeve Madigan, and Nikita Schmal.
One of the big questions in global SMEFT analyses is how to use published likelihoods in the SFitter framework and improve the global analysis or at least make it much more efficient (2023). We include public ATLAS likelihoods for the top sector of SMEFT, for instance the top pair production rate. While the results are consistent with extracting information from the ATLAS publications, the likelihoods allow us to carefully study all uncertainties, to confirm that in the top sector the theory uncertainties dominate the global SMEFT analysis. |
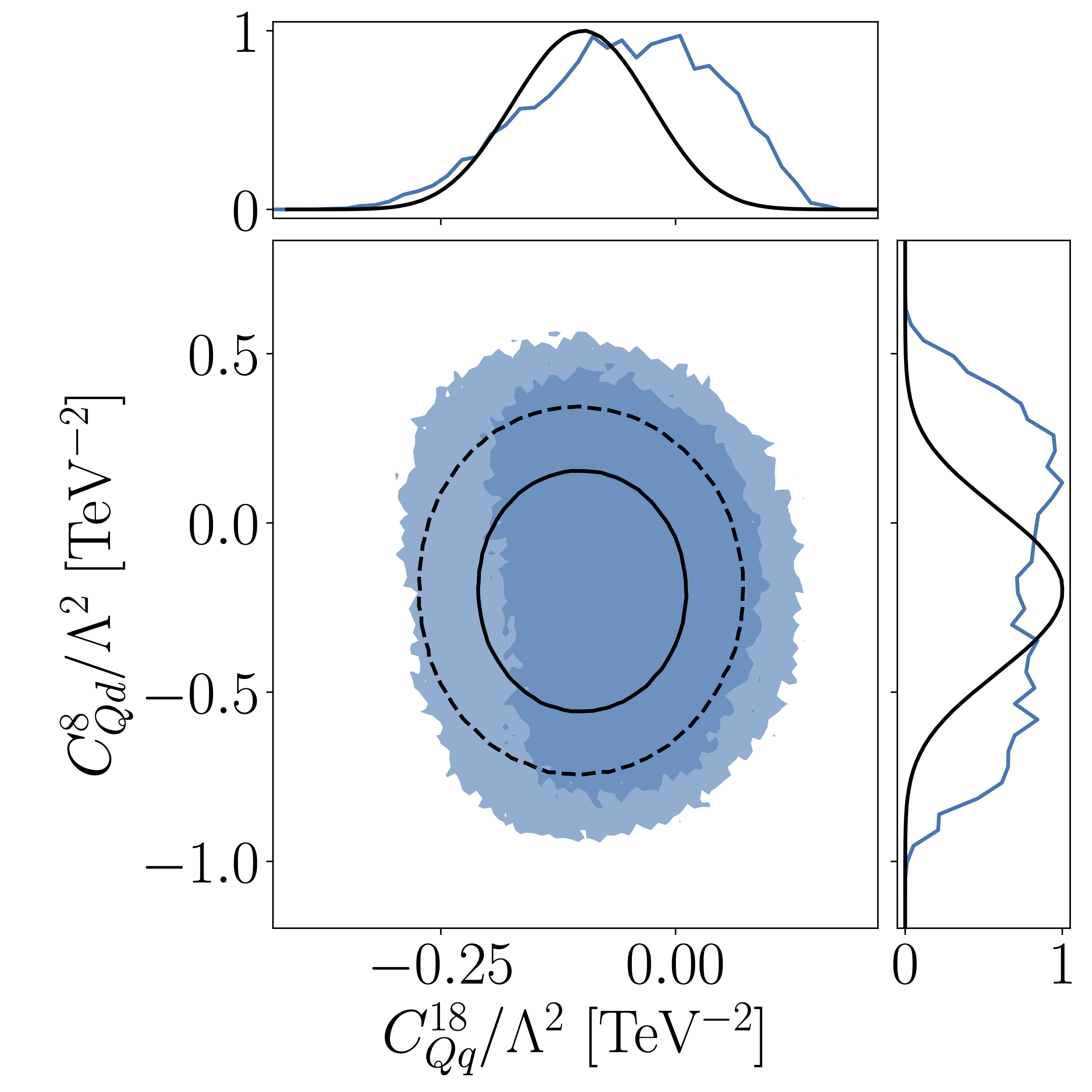 |
A big problem for global analyses are theory uncertainties, affecting predictions based on perturbative QCD (2022). While the combined renormalization and factorization scale dependence describes this uncertainty reasonably well, this estimate fails for electroweak processes. We propose a new approach, based on representative classes of processes, and find that it describes the step from LO to NLO QCD predictions well, with very few remaining outliers which can be linked to well-understood effects. |
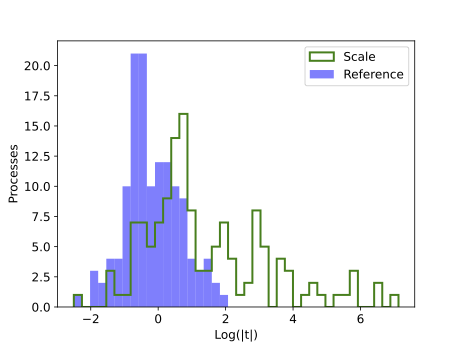 |